はじめに
はじめまして、クラウドインテグレーション事業部の竹内です。
2022/11/27-12/02に開催された、 AWS re:Invent 2022に参加させていただきました。
働いているときはAWSって便利だなーくらいの感覚でしたが、re:Inventを通して世界中の人と空間を共有することで、あ、私すごいサービス触ってたんだ って実感しました。日本に帰ってきてからもあの熱気や熱量というのは忘れられません。

海外経験は10年以上ぶりで初参加ということもありなかなかに不安でしたが、会社の先輩の助言を頂きつつなんとか楽しみながら、色々学ばせて頂いた1週間となりました。セッションを受ける際も、一筋縄ではいきませんでしたが、色々なツールやサイトを駆使ししてなんとかインプットできたかなという感じでした。
そこで今回はBreakout Sessionのひとつである、
Democratizing your organization’s data analytics experience
についてまとめてみました。

業務でデータ分析系のサービスを扱うことがあり、そのルーツや思想について興味があり、今回はこちらのセッションに参加してきました。
タイトルを直訳すると組織のデータ分析経験の民主化 と言う意味になります。 ビジネスにおける民主化というのは一部の限られた人たちだけではなく、多くの人も利用できるようにするという意味です。
このセッションでは、AWSの使いやすさと優れたコストパフォーマンスにより、ユーザーがどのようにデータ分析を民主化できるかを説明しています。AWSがどのようにデータ取り込みを簡素化し、あらゆるスキルレベルのユーザーが機械学習を容易に利用できるようになるかを紹介しています。
内容
お客様の分析の民主化に向けて、どのような差別化要因があり、どのようにAWSがそのサービスやソリューションに組み込んでいるのかというお話です。
 オンプレミスで行うべきか、それともクラウドで行うべきか?
オンプレミスで行うべきか、それともクラウドで行うべきか?
現在では、オンプレミス、クラウドのいずれにおいても、非常に多様な選択肢があります。また、データを保存するだけでなく、データを扱う方法もあります。では、何が企業をクラウドへと向かわせるのでしょうか。ほとんどの場合、データはオンプレミスからクラウドに移行しています。データには重力があり、アプリケーションとデータがクラウドに移動しています。隣接するすべての分野、機械学習データウェアハウス、データを扱うすべてのアプリケーションもクラウドに引き込まれています。そして、データの重心が移動するにつれて、この動きはますます大きくなっていきます。 ここではtaz(発表者)はデータを重力と表現していました。

ほとんどのユーザーは、従来のオンプレミス、メンテナンス、ライセンスといったものから脱却しつつあります。新しい機能をより早く実現するために、クラウドファースト、あるいはクラウドのみの戦略を行っています。そして、今年の9月現在、ビッグデータとアナリティクス全体の44%をクラウドが占めています。2024年までに企業はデータ分析ワークロードの70%以上をクラウドに移行する予定です。

単にコストが安いという意味だけでなく、データ共有、運用の自動化、スケールなど、さまざまな課題が挙げられます。AWSは分析を利用可能で、アクセスしやすく、手頃な価格で提供しています。さらにAWSクラウドは、データの重力効果やアナリティクス、機械学習のニーズでクラウドに移行する顧客の対応を認識したソリューションやサービスを提供します。これらはあらゆるデータ機能を提供することができ、スキルや経験の理由から生じる可能性がある障壁を取り除くことができます。

AWSで利用できるサービスやソリューションの多様性は、お客様独自の状況に最適な選択をする能力を持つことが重要となってきます。コスト、スキル、セキュリティ、コンプライアンスなど、これらはすべて重要な要素だが、使いやすさとコストパフォーマンスに勝るものはないです。これらは、クラウド導入に関連するビジネス上の意思決定に大きな影響を与える差別化要因です。
 ユーザーにとって3つの主要な属性、「参入障壁の低さ」「運用負担の軽減」「ローコード・ノーコードエクスペリエンス」に集約されます。
ユーザーがすぐに使い始められるような直感的に操作できるようなサービスやソリューションを構築、また厳しいスキルを要求しないことが現代のユーザーのニーズだと考えています。
ユーザーにとって3つの主要な属性、「参入障壁の低さ」「運用負担の軽減」「ローコード・ノーコードエクスペリエンス」に集約されます。
ユーザーがすぐに使い始められるような直感的に操作できるようなサービスやソリューションを構築、また厳しいスキルを要求しないことが現代のユーザーのニーズだと考えています。
運用負担の軽減とは、お客様が運用上のオーバーヘッドを相殺することができることを指します。例えば、監視イベントを設定し、そのイベントに反応し、通知し、自己修復アクションを実行する、などです。
ローコードやノーコードの経験は、従来のソフトウェア開発の多くの側面を排除することで、迅速に移動することができます。AWSの多くのサービスは、迅速なデプロイメント、より速いリピートサイクルを促進し、ユーザーの生産性を高め、また高度な自動化とカスタマイズにつながり、それによって運用コストを削減することができます。
 tazはAWSサービスの一例として、EMRに焦点を当てました。
tazはAWSサービスの一例として、EMRに焦点を当てました。
- 彼(taz)の好きなサービス
- 最新のオープンソースのフレームワーク、テーブルフレーム形式や様々なフレームワークを使って、ペタバイト級のデータをスケーリングしている
- これらはS3データレイクにあるデータに対して直接実行される
- データを移動したり、データを変換したりする必要はない
- EMRは2009年にリリースされ革新を続けている
- EMRを導入するためにアプリケーションコードを変更する必要がないこと
- Athenaと同じように、スキャンした分だけを支払えばよい
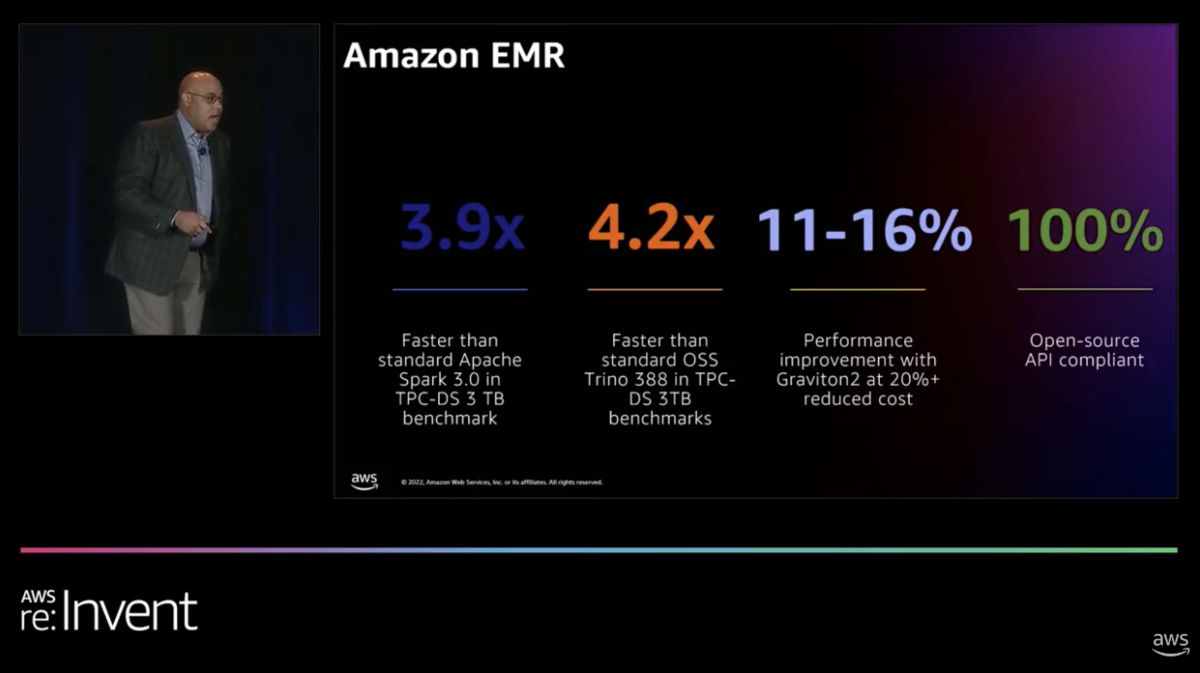
- Apache Sparkを使用した場合標準的なApacheと比較して3.9倍高速
- オープンソースのSpark Trinoでは、標準的なPrestoよりも4.2倍速く
- Gravitonを活用することで、費用対効果をさらに向上
- クラウドへの移行時にやり直しを強いられることがないように、コンプライアンスを100%向上

- クラスタごとにコストを配分できる
- 価格設定も非常にシンプルで使用するインスタンスタイプごとに設定できる
- クラスタのサイズも自分でコントロールできる

EMRは、さまざまなコストプロファイルに対応した選択肢をユーザーに提供している。 性能を比較し、サービスの柔軟性をここでは提唱していた。

Amazon Athenaは昔からあるサービスです。なぜこれほどまでに成功したのか?それはサーバーレスだからです。メンテナンスも管理もゼロです。Athenaをデータに接続してSQLを実行するだけで、使用するクエリに対してのみ支払いが発生します。1テラバイトのスキャンで約5ドル程度で非常にリーズナブルで人気のサービス。そしてサービスの価格は一度も変わっていないそうです。 圧縮とパーティショニング、そしてデータを列方向に変換することで、30~90%の削減効果を得ることができます。そして、必要であれば、価格性能もさらに向上させることができます。これが不変的なAthenaの人気だと提唱していました。
またオープンで柔軟性があり、CSVやJSONといったさまざまなデータ形式が、ユーザーにとって非常に標準的な形式な点、「使いやすさ」も重要なポイントです。このサービスを開始して以来、継続的な改善とお客様からのフィードバックは素晴らしい進化を遂げ続けています。DynamoDBやRedshiftなど、さらにより多くのデータソースが追加されました。そしてさらに昨今ではSparkを使って、より質の高い分析を行うことができるようになりました。
Athenaはシンプルでユーザーエクスペリエンスに優れていることで知られていますが、これらのデータコネクタは、ネイティブサービスへの接続を拡張するだけでなく、DynamoDBとS3を直接結合して、我々のクラウドだけでなく他のクラウドでも大きな価値を提供することができるようになります。

多くの人が、これはAWS内のネイティブサービスだけのものだと思っていますが、このリストを見ると、SAP HANA、Oracle、Teradata、Google Big Queryなど、より多くの価値を得られるように、私たちは本当に能力を拡張しています。これらのコネクタは無料で使用でき、データスキャンを行う場合にのみ料金を支払います。


サーバーレス戦略の採用が増加傾向にあります。デプロイメントにかかる時間や、コンピュートリソースの割り当てにかかる時間が短縮され、このメリットこそサーバーレスの強みです。
サーバーレスは、より俊敏で、高度な柔軟性を必要としないアプリケーションに適していると考えています。サーバーレスは、高い柔軟性を必要としない、よりアジャイルなアプリケーションに適しています。設定した容量を固定したくないので、その都度計算するべきです。
まとめ
AWSの各種サービスやメリットを追求することで、分析の民主化、利用可能性、巨大なデータ資産が組織にとって重要であることを説明していました。価格性能と使いやすさがAWSサービスのメリットであり、長い歴史の中でよりそれに改善に力を入れ続けているとtazは言い続けています。その中でも如何に的確に、適切なサービスを使用するかで、AWSエンジニアの腕が試されそうです。
追記
本セッションは、録画映像が YouTube で公開されています。
www.youtube.com