こんにちは、フォージビジョンの藤岡(@fuji_kol_ry)です。
先月5月末にAWS公式から、Lambdaの開発を加速するライブラリ"Powertools"にて、Bedrock Agentとの連携が発表されました。
これは個人的には非常に嬉しいニュースで、Bedrock AgentやTool useの開発効率が大幅に向上することが期待されます。
早速試したいと思っていたところ、ちょうどのタイミングでJAWS-UGで登壇する機会をいただいたため、せっかくならと思ってPowertoolsの魅力を発信してきました!!以下が発表資料です。
以降の本ブログでは、発表資料の内容を補足する形で、Powertools及びBedrock Agent連携の魅力をお伝えいたします。一度スライドを読んでいただいた上で、以降をお読みいただけますと幸いです。(※発表資料と重複する部分もありますが、ご了承ください。)
そもそもPowertoolsって何?
Powertools for AWS Lambdaは、AWS Lambdaの開発を加速するためのライブラリです。今回のBedrock Agent連携も含めて、主要な機能(Core utilities)として以下を提供しています。
| ユーティリティ | 概要 |
|---|---|
| トレース | X-rayと連携した処理のトレース |
| ログ | 構造化ロギング |
| メトリクス | カスタム名前空間を利用したメトリクス集計 |
| Event Handler (AppSync) | AppSync Eventからのパブリッシュ&サブスクライブに対するイベントハンドリング |
| Event Handler (Bedrock Agent) | Bedrock AgentからのTool useとしてのLambda呼び出し&結果の受け渡しに対するイベントハンドリング |
Powertools公式情報
Powertoolsは2025年6月時点で4つの言語をサポートしているため、ここで公式ページの紹介と、PythonとTypeScriptについては私の主観的な特徴をお伝えします。
▼Python
- ユーティリティの充実度が一番高い(ユーザーの多さを表しているでしょう)
- デコレーターによって、実装を邪魔せずにライブラリを導入できることで、スマートに開発実装できる印象
▼TypeScript
- バックエンドでTypeScript、インフラでCDKを使ってTypeScriptと、言語を揃えることができるのが魅力
- Pythonと異なり、デコレータではなく宣言的にユーティリティを利用する形のため、インフラエンジニアでも導入しやすいかと個人的に思っています
他にもJavaと.NETもサポートされていますが、私が利用経験が無いため、サイトのみご紹介とさせていただきます。
▼Java
▼.NET
実際にエージェントを作ってみた
今回は検証目的として、Google Books APIを使って、概要や著者、ページ数など具体的な情報まで教えてくれる書籍推薦エージェントを作成しました。
処理フローは以下のシーケンスの通りです。
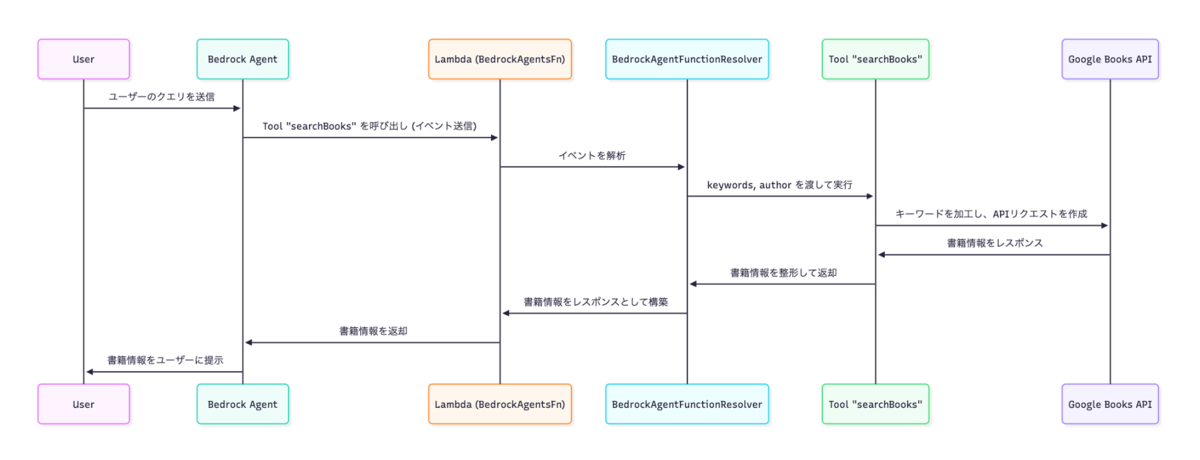
詳しく書くと、以下の流れとなります。
- Bedrock Agentコンソールで、ユーザーが読みたい書籍の希望を入力
- Bedrock Agentがユーザーの意図を理解し、キーワード(+著者)を抽出
- Lambdaへイベント送信
- Lambdaのリゾルバがイベントを解析し、Bedrock Agentから指定されたToolを呼び出す
- Tool実行(今回でいうsearchBooks)
- searchBooksとして、Google Books APIを利用して書籍情報を取得(今回は上位10冊を取得しています)
- 取得した書籍情報を整形
- ToolからBedrock Agentへ、結果を返却
- Bedrock Agentが、ユーザーの入力した希望と取得結果10冊を比較して、最も適切な書籍3冊を絞り込む
- 絞った3冊の書籍情報を、ユーザーの希望に沿った形で推薦
他の細かい補足としては、
- LLMは、Claude 3.5 Sonnet v2を使用。
- 書籍推薦エージェントのプロンプト(Bedrock AgentへのInstruction)は以下のように設定。
You are an expert book-search agent and reference librarian. ⚫︎ STEP 1 — Understand Intent Carefully read the user’s query and infer the underlying purpose, audience level, location, genre and any constraints. ⚫︎ STEP 2 — Extract Keywords (3-5) Return *multi-word phrases* that best capture the user’s intent (e.g., “fine-dining restaurants in Kyoto,” not just “Kyoto”). Include proper nouns, domain terms, and any author names explicitly mentioned. Ignore generic or irrelevant words (e.g., ‘book’, ‘want’). Order the keywords by importance. Generated keywords must be in Japanese. "キーワード1,キーワード2,キーワード3" is an example of the expected output format.(joined by comma) ⚫︎ STEP 3 — If intent is ambiguous or missing critical details, ask ONE clarifying question and WAIT for the answer before proceeding. ⚫︎ STEP 4 — With the final keyword list (+ author if any), call the Lambda tool to search books. ⚫︎ STEP 5 — Recommend exactly 3 books in a friendly librarian tone, explaining briefly why each matches the user’s needs.
Toolの実装は、スライドのページと同じく、以下になります。
import type { Context } from 'aws-lambda'; import { BedrockAgentFunctionResolver, BedrockFunctionResponse } from '@aws-lambda-powertools/event-handler/bedrock-agent'; import type { BedrockAgentFunctionEvent } from '@aws-lambda-powertools/event-handler/types'; import { Metrics, MetricUnit } from '@aws-lambda-powertools/metrics'; import { Tracer } from '@aws-lambda-powertools/tracer'; import { searchBooks } from './bookModules.js'; import { logger } from './logger.js'; // appを作成(Agentからのエントリポイントとして機能) const app = new BedrockAgentFunctionResolver({ logger }); const tracer = new Tracer({ serviceName: 'searchBooksAgent', }); const metrics = new Metrics({ namespace: 'searchBooks', serviceName: 'searchBooksAgent', }); // Toolの定義(searchBooks) app.tool<{ keywords: string, author: string }>( async ({ keywords, author }, { event }) => { // 以降の全ロギングに対して、以下パラメータを表示 logger.appendKeys({ keywords, author, tool: 'searchBooks' }); logger.info('searchBooks called'); try { // Tool logic const books = await searchBooks(keywords, author, 10); // searchBooks内で詳細な実装を行っています metrics.addMetric('searchBooksSucceeded', MetricUnit.Count, 1); return books.map(book => ({ ...book })); } catch (error) { logger.error('error retrieving books', { error }); metrics.addMetric('searchBooksFailed', MetricUnit.Count, 1); const { sessionAttributes, promptSessionAttributes, knowledgeBasesConfiguration, } = event; return new BedrockFunctionResponse({ responseState: 'FAILURE', body: 'Error retrieving books', sessionAttributes, promptSessionAttributes, knowledgeBasesConfiguration, }); } finally { logger.removeKeys(['keywords', 'author', 'tool']); // addMetricした結果を反映 try { metrics.publishStoredMetrics(); } catch (metricsError) { logger.error({ message: 'Failed to publish metrics', error: metricsError instanceof Error ? metricsError.message : 'Unknown error' }); } } }, { // リゾルバがTool useとして識別するためのメタデータ name: 'searchBooks', description: 'Search for books by author or keywords', } ); export const handler = async (event: unknown, context: Context) => { logger.logEventIfEnabled(event); logger.setCorrelationId((event as BedrockAgentFunctionEvent).sessionId); logger.appendKeys({ requestId: context.awsRequestId }); return app.resolve(event as BedrockAgentFunctionEvent, context); };
実装の各パートの説明は、スライド資料のこちらやこちらをご確認ください。
リソースの構築や、書籍検索のAPIコール部分などについては割愛します。 詳しく知りたい方は、以下のAWS公式サンプルをご確認ください。(プロンプトやTool中身は異なりますが、アーキテクチャは今回の書籍推薦エージェントとほぼ同じです。)
出来上がった書籍推薦エージェントを確認してみる
エージェントとToolをデプロイしたのちに、Bedrock Agentコンソールから動作を確認してみます。
まず希望する書籍の情報を入力します。すると、エージェントが特にオススメする3冊を紹介してくれました。(3つとも存在する書籍でした。)

チャット部分の「トレースを表示/非表示」を選択することで、エージェントの中の思考(トレースステップ)を確認することができます。
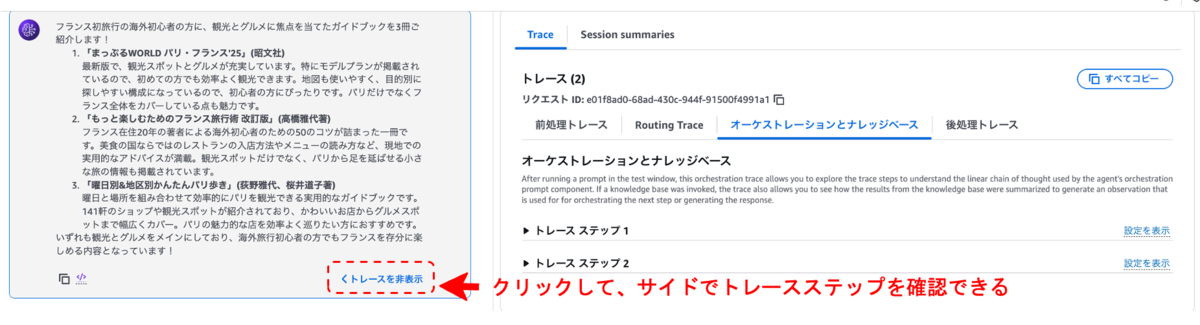
今回では、以下のように確認できました。
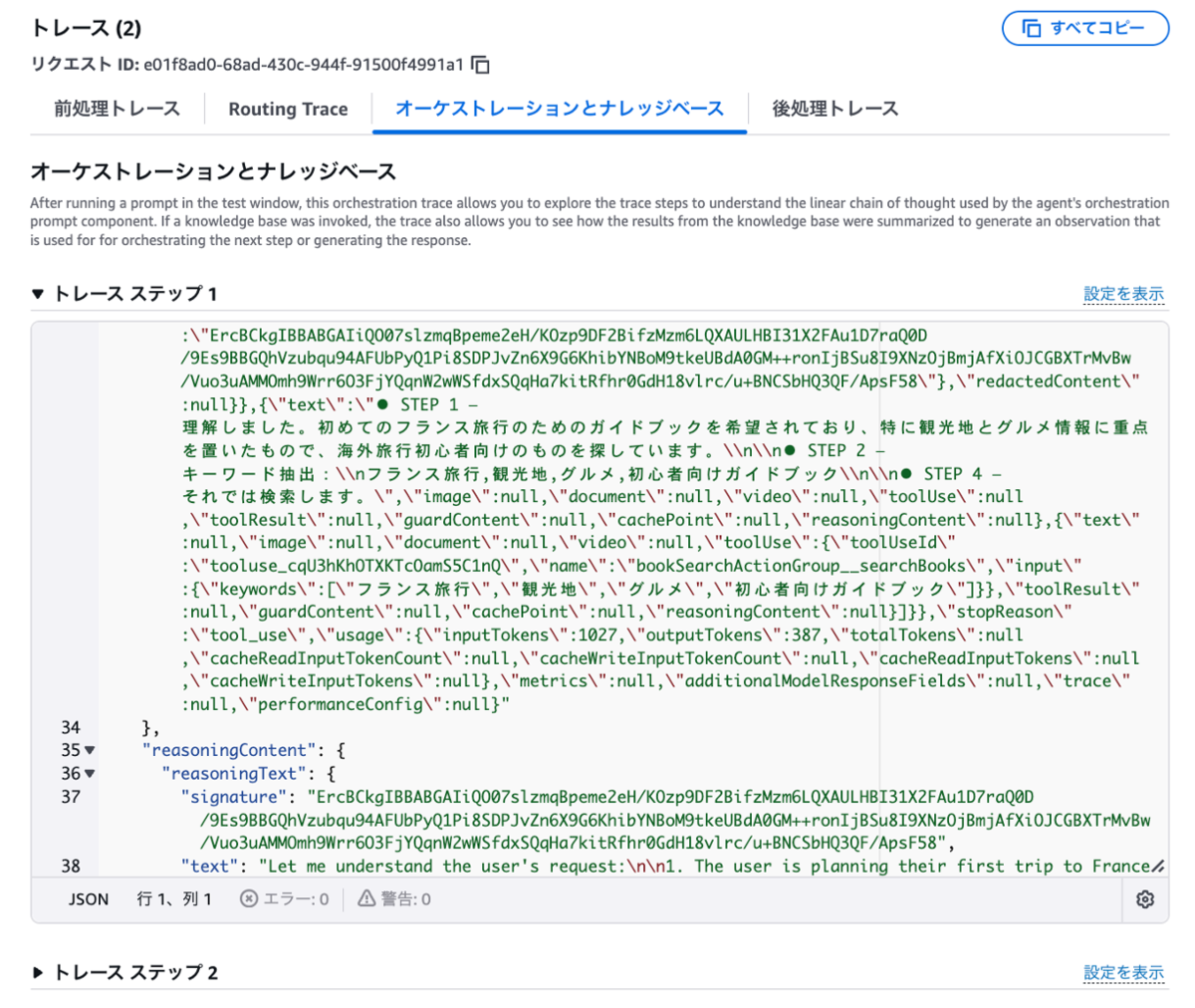
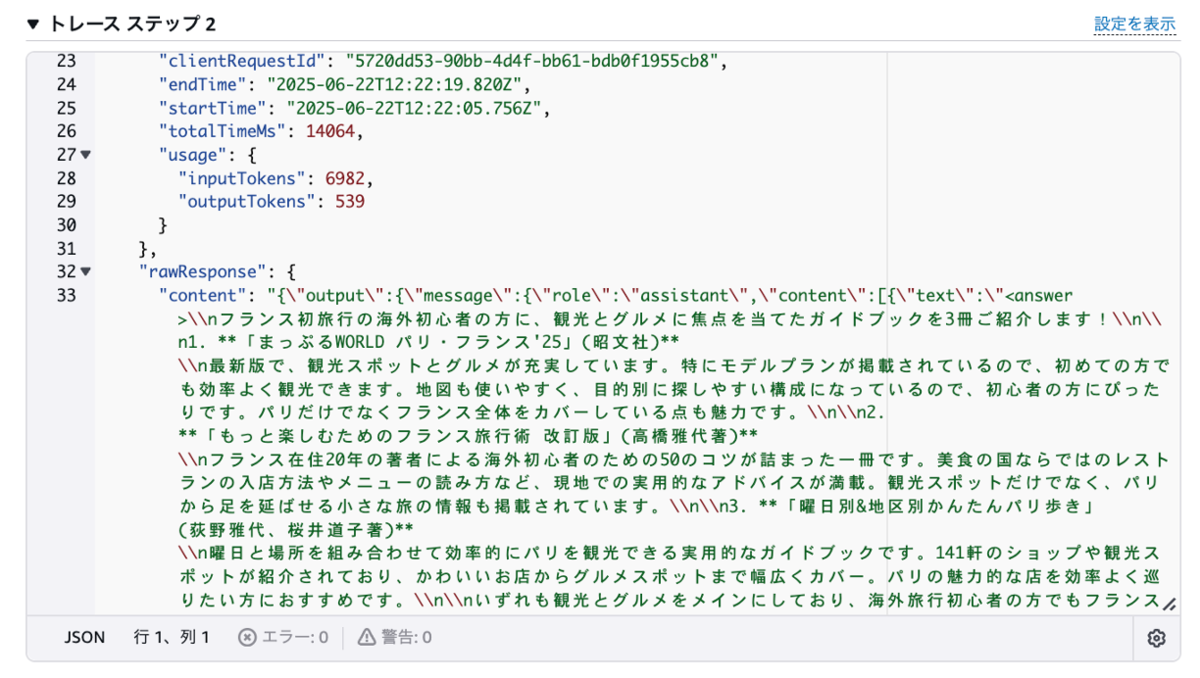
推薦された本の中から、もう少し詳しい情報を教えてもらいましょう。
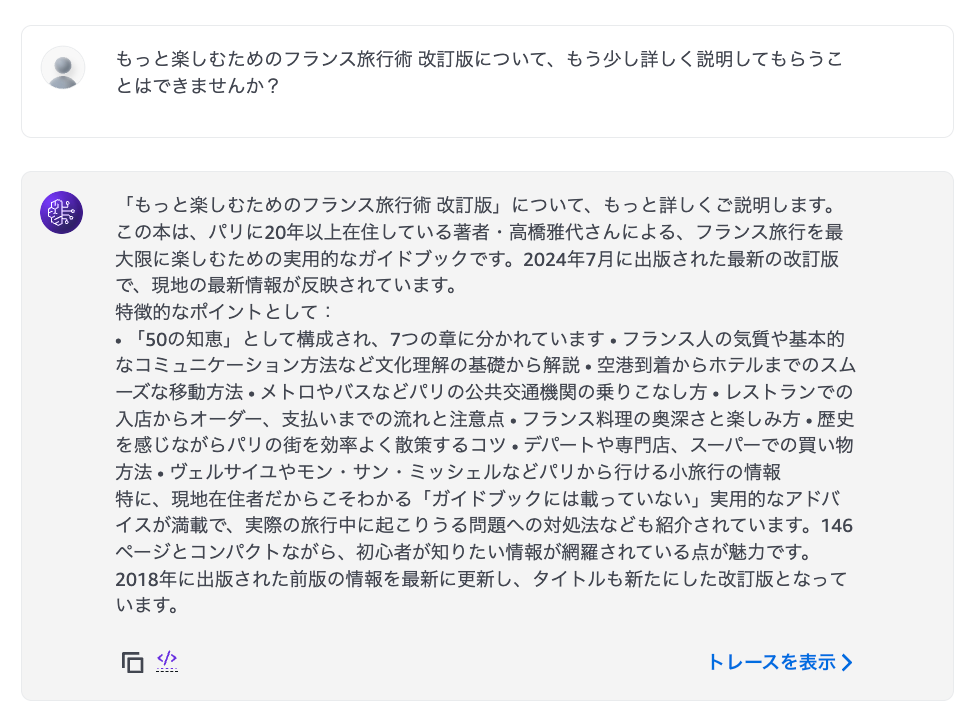
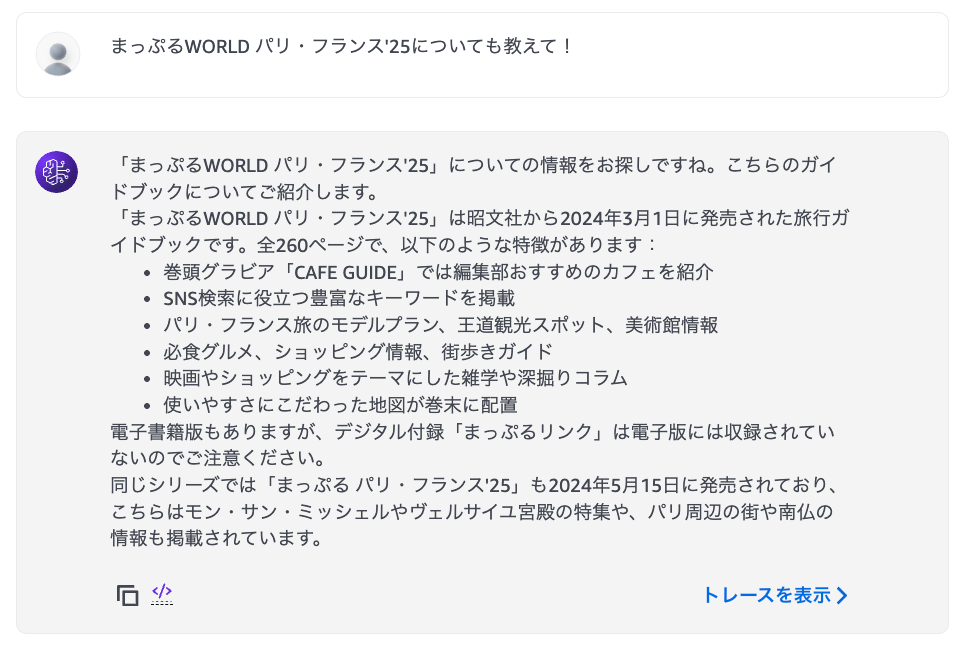
良いですね。Tool useを使うことで、Web検索や外部API連携、RAGなどによって情報を補完できるので、今回のように具体的な情報まで提示してもらうことが出来ました。
Powertools導入のメリット
今回はPowertoolsを使うことでシンプルに実装していますが、もしPowertoolsを使わない場合、以下のような手間が発生します。
- リゾルバが無いので、Eventから1つ1つパラメータ取得するための実装
- アクショングループ
- Tool名
- 例えば、Powertools無しならば、Tool名を取り出して、if-elseの分岐処理でToolを呼び出す必要がありますが、Powertoolsではメタデータを宣言するだけで、リゾルバが自動的に指定されたToolの特定や呼び出しをおこなってくれます。
- BedrockAgentへRaiseするExceptionクラスなどを、自前で作成・メンテナンスが必要
- そもそも、Bedrock Agentからのイベントが期待する形式なのかチェックしないといけない
- Eventが期待する形式か
- パラメータは適切か(バリデーション)
上記のようなメリットが得られるPowertoolsを導入することで、実装の削減のみ限らず、メンテナンス性や可読性を向上させられます。
またPowertoolsで省力化できる実装は、AIエージェントを開発する上で必要な部分でありますが、プロダクトの価値と直結するものではありません。そのため、Powertoolsを積極的に活用することで、プロンプトエンジニアリングやTool本体の実装に集中して、AIエージェントの開発を加速させられます。
加えてPowertoolsは以前より、トレース・ログ・メトリクスの導入もサポートしています。これにより、開発者視点だけでなく、Tool利用する生成AIエージェントを運用するオペレーターの視点からも、Powertoolsを利用しない選択肢は無いかと思います。
まとめ
Powertools for AWS LambdaのBedrock Agent連携が発表されました。これによって、AIエージェントの開発がさらに効率化されることが期待されます。
また、Bedrock Agentの連携部分に限らず、Powertoolsにはトレース・ログ・メトリクスを導入する上でのAWSのベストプラクティスが組み込まれているので、採用しない手は無いかと思います。
Powertoolsを使いこなして、AIエージェントの開発を加速させましょう!
以上、フォージビジョンの藤岡でした。