こんにちは、開発グループの寺田です。
本記事では、2025年1月に東京リージョンで利用可能になった「S3 Tables」 について、
AWSの公式チュートリアル「S3 Tables の使用開始」を実践した内容を紹介します。
S3 Tablesとは?
S3 Tablesは、2024年12月3日 AWS re:InventのCEO Matt Garman氏のKeynoteで発表された新機能です。
このサービスは、Apache Icebergをサポートしたマネージドサービスであり、
Apache Parquet形式 (表形式) のデータに最適化されたストレージサービスです。
Amazon AthenaやApache Sparkなどの一般的なクエリエンジンを使い、シンプルなSQLクエリを実行できます。
特に分析ワークロード向けに最適化されており、従来のS3に比べてパフォーマンスとクエリ効率が向上しています。
チュートリアルの実践
今回はAWSの公式チュートリアルの手順に従ってS3 Tablesの設定を行います。 docs.aws.amazon.com
テーブルバケット作成&AWS分析サービスとの統合
AWSの管理コンソールにログインしてAmazon S3 > テーブルバケットを選択し、
テーブルバケット作成ボタンをクリック
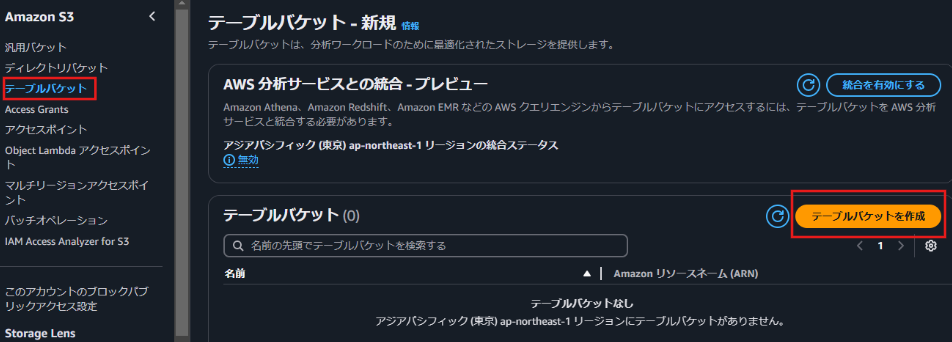
テーブルバケット名を入力して、テーブルバケット作成ボタンをクリック。
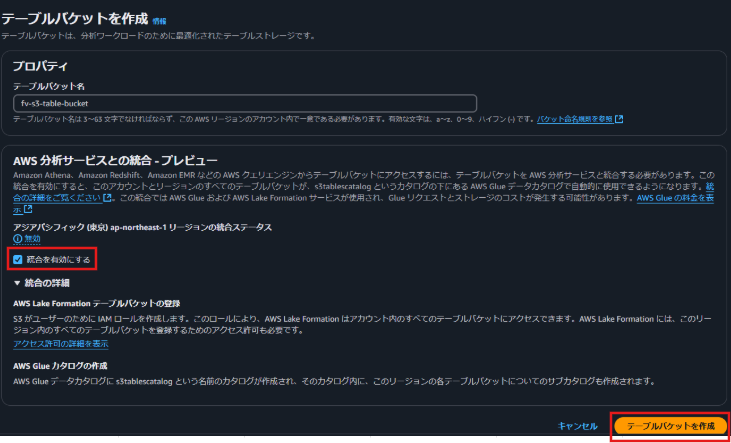
テーブルバケットを作成できました。
AWS分析サービスとの統合を有効化すると、以下のリソースが自動的に作成されます。
【作成されるリソース】
1. AWS Lake Formationのカタログ(s3tablescatalog)
2. IAM ロール(S3TablesRoleForLakeFormation)
また、統合を無効化する場合は、これらのリソースを削除することで元の状態に戻すことが可能です。
今回は環境を初期状態に戻すことを目的として、検証後に以下のリソースを削除し、無効化できることを確認しました。
【削除したリソース】
1. S3テーブルバケット(名前空間とテーブルを含む)
2. AWS Lake Formationのカタログ(s3tablescatalog)
3. AWS Lake FormationのData lake locations(削除するバケットのlocation)
4. IAM ロール(S3TablesRoleForLakeFormation)
⚠️ 注意
本ブログで紹介する無効化の方法は、AWSの公式ドキュメントには記載されていません。
独自に検証した結果であり、推奨される方法ではないため、ご利用の際は十分にご注意ください。
名前空間とテーブルの作成
AWS CLI を使用してテーブル バケットに新しい名前空間を作成します。

続いてテーブル スキーマを使用して新しいテーブルを作成します。

名前空間とテーブルを作成できました。
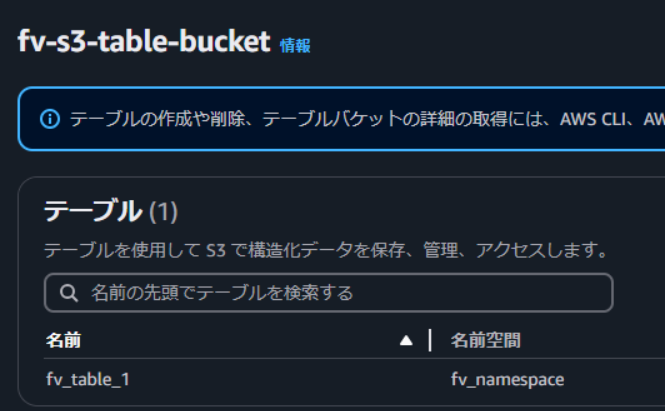
テーブルにLake Formationの権限を付与
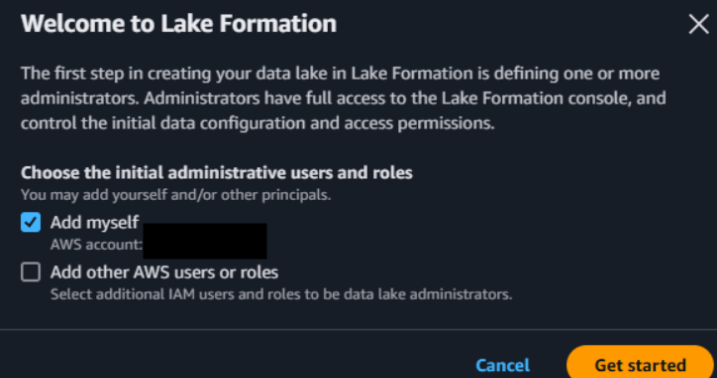
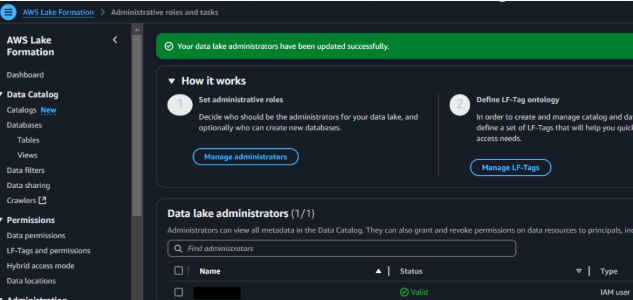
初回はデータ レイク管理者を作成するポップアップが表示されるので、
自身のアカウントを管理者に追加してGet startedボタンをクリック。
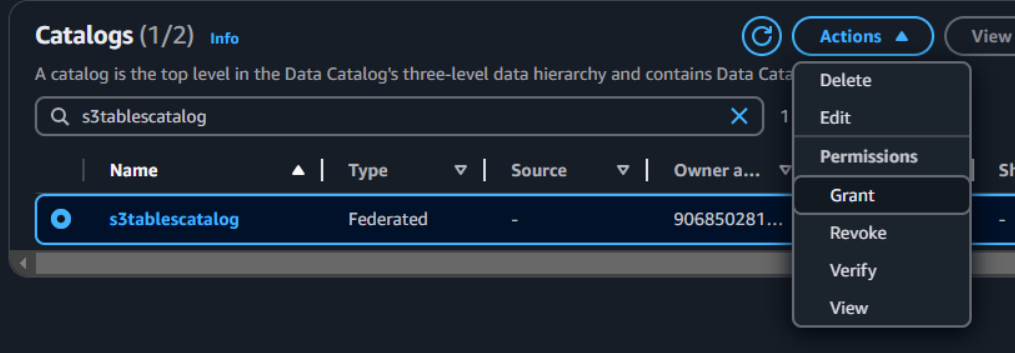
テーブルバケット作成時に作成されたカタログを選択してGrantをクリック。
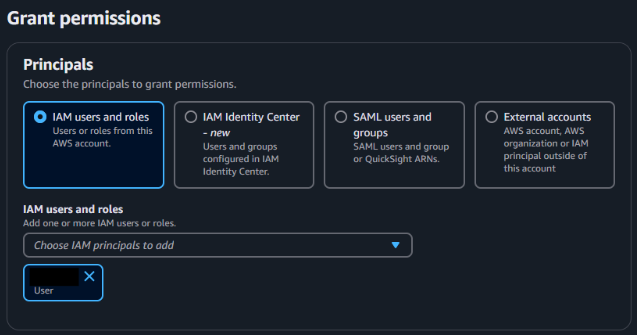
チュートリアルに従って選択する。
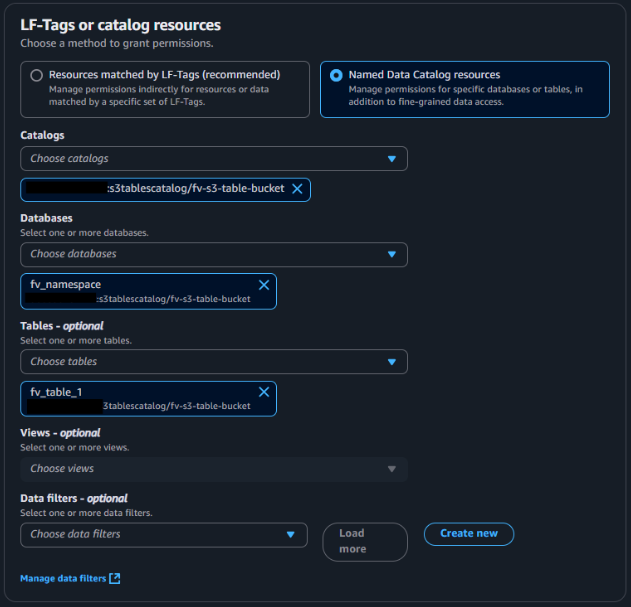
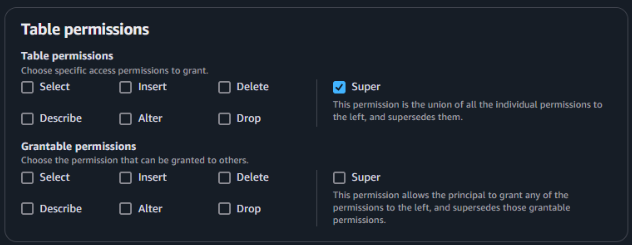
テーブルにLake Formationの権限を付与できました。
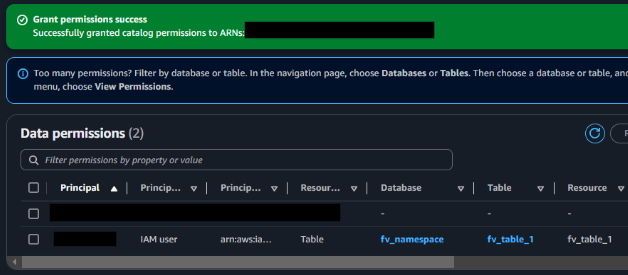
Athena で SQL を使用してデータをクエリ
クエリはチュートリアルに記載のサンプルを利用します。
INSERTコマンドを使用してテーブルにデータを追加します。
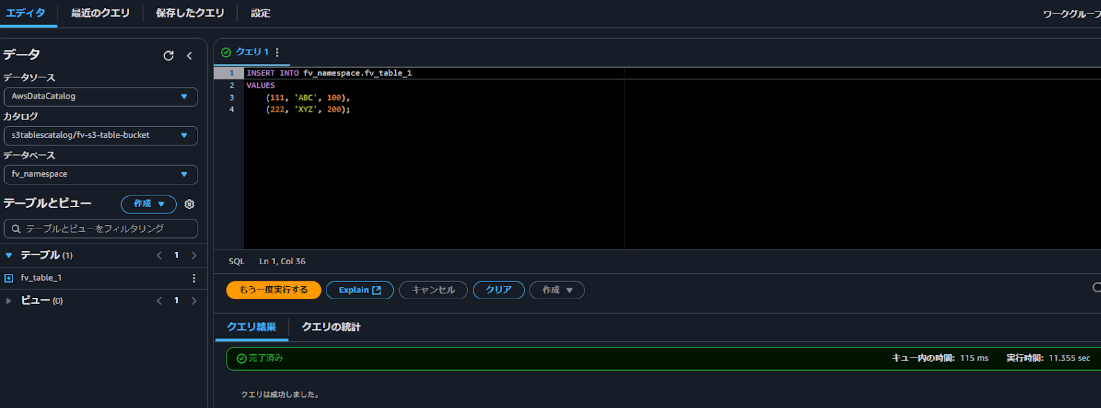
SELECTコマンドでテーブルに追加したレコードを確認することができました。
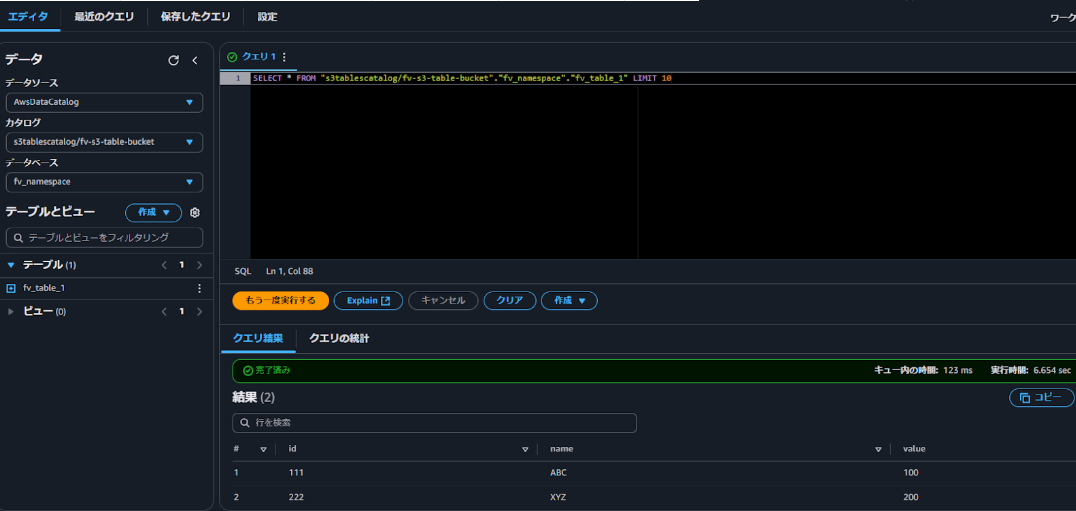
まとめ
テーブルバケットの作成からクエリの実行まで、チュートリアル「S3 Tables の使用開始」の内容を一通り確認することができました。 想像していたよりもクエリの実行速度が遅かった点が気になりましたので、パフォーマンスが向上する方法について調査したいと思いました。
引き続きS3 Tablesの機能を検証し、その結果を随時ブログで紹介していきます!