こんにちは、AWS チームの尾谷です。
あるシステムで、[ダウンロード] ボタンをクリックしたあと、データのダウンロードまで数分間かかるシステムのアーキテクチャについて相談を受けました。
あるシステムは平常時 2 台の EC2 インスタンスで Web サイトがホスティングされており、その中のマスターサーバーである 1 号機に関してはホスティング以外の管理処理も行なっているため、単一のオペレーションで数分かかるようなダウンロード処理によるリソースの占有は望ましくないことと、夜間などはリクエスト数が極端に下がるため、インスタンスをスケールアップする提案もコストインパクトが大きく難しい状況でした。
「だったら、ダウンロード部分のみ Lambda で実装すれば良いのでは?」と思い、提案してみました。
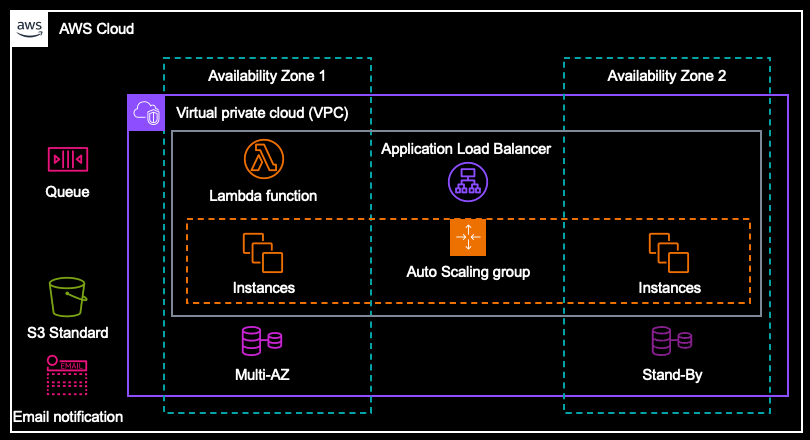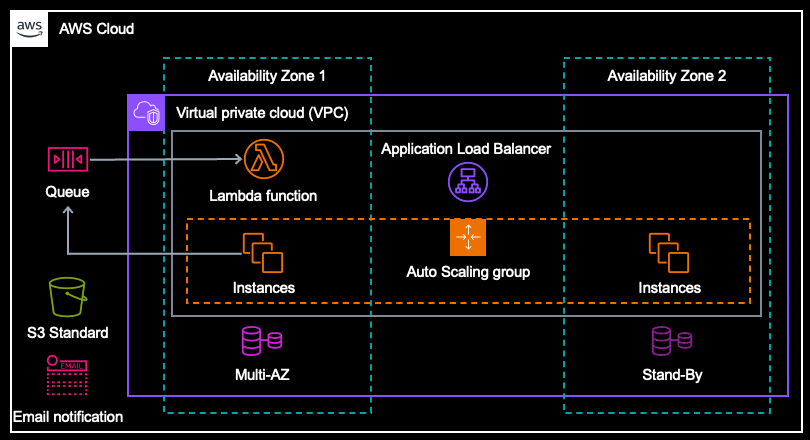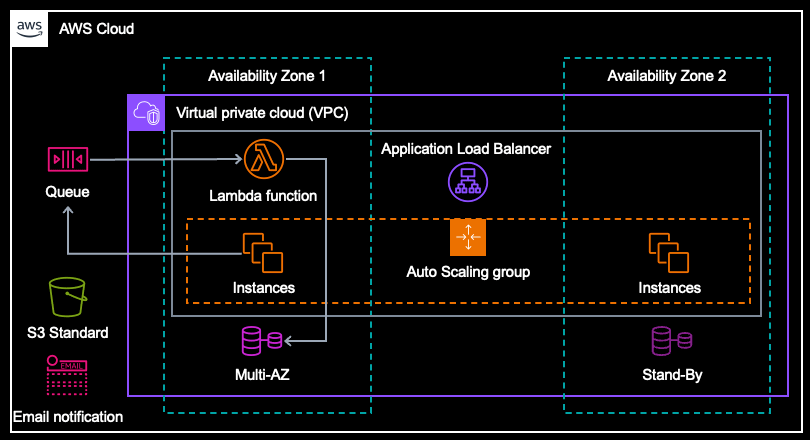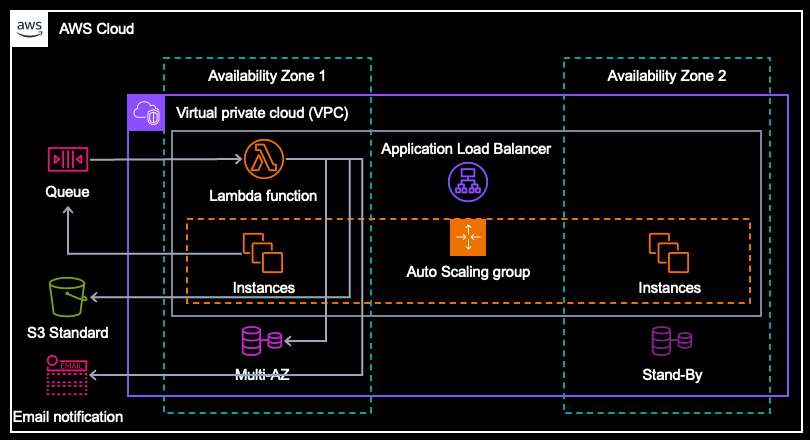
- [ダウンロード] ボタンをクリックされると、SQS にキューを追加する
- SQS から Lambda 関数が実行される (同時実行数を 1 にする)
- RDS MySQL からデータを取得し、加工する
- S3 バケットにデータを保存する
- E メールでファイルが生成できたことを通知する
今日、このブログでご紹介するのは 2 の SQS から Lambda が実行される部分と、3 の Lambda が RDS に接続する部分の解説です。
SQL Alchemy を使って RDS に接続する
SQL でデータを取得し部分して S3 に保存する部分はアプリチームが実装しますが、Lambda が MySQL に接続するところまではインフラ側の対応のため、別の案件で実績のあった SQL Alchemy を使った接続を提案してみました。
VPC Lambda をデプロイ
RDS に接続するため、VPC Lambda をデプロイしました。
最近は、めっきり arm で Lambda を作りますが、SQL Alchemy を利用する関係で、x86 にしました。
IAM ロールには、AWSLambdaBasicExecutionRole と AWSLambdaVPCAccessExecutionRole をポリシーとしてアタッチしました。

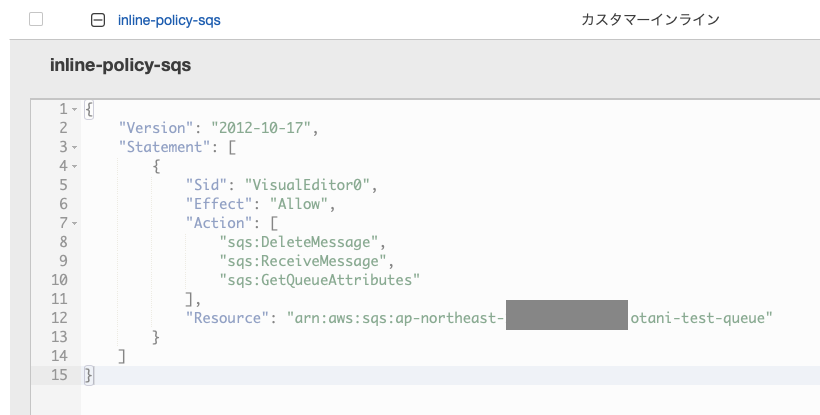
また、後ほど SQS を利用するので、こちらのドキュメント に記載の通り sqs:DeleteMessage と sqs:GetQueueAttributes と sqs:ReceiveMessage をインラインポリシーで許可しました。
ここでは、パブリックサブネットに起動して
以下、Establishing Connectivity - the Engine のドキュメント を参考に、ChatGPT の協力を得ながらコーディングしました。
import os from sqlalchemy import create_engine, text RDS_HOST = os.environ['RDS_HOST'] RDS_USER = os.environ['RDS_USER'] RDS_PASSWORD = os.environ['RDS_PASSWORD'] RDS_REGION = os.environ['RDS_REGION'] RDS_DB = os.environ['RDS_DB'] def lambda_handler(event, context): engine = create_engine(f"mysql+pymysql://{RDS_USER}:{RDS_PASSWORD}@{RDS_HOST}/{RDS_DB}") with engine.connect() as connection: query = "SELECT * FROM user" result = connection.execute(text(query)) for row in result: print(row)
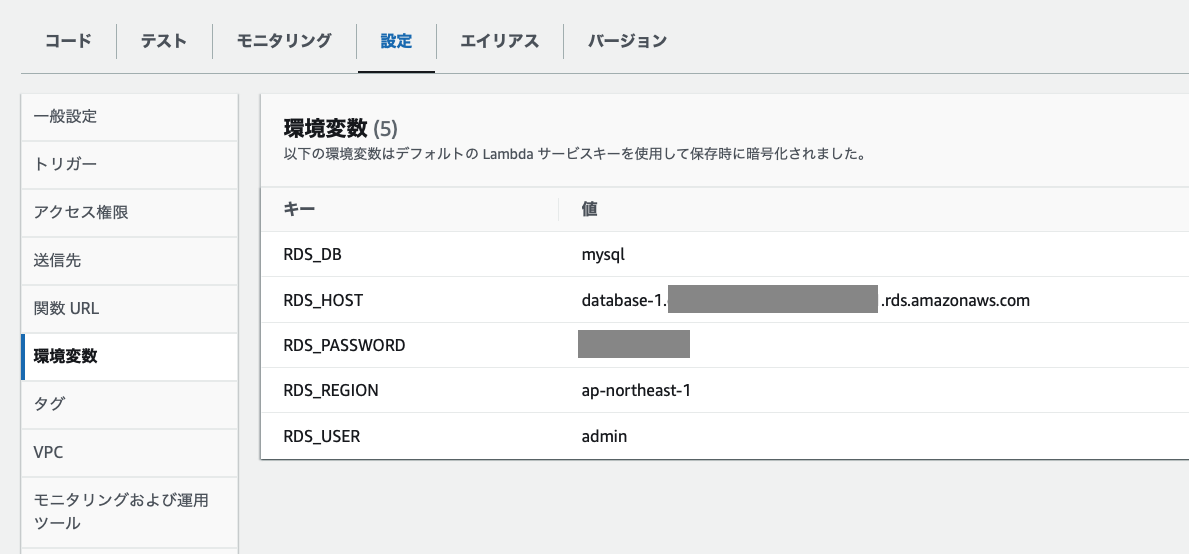
環境変数には各種パラメーターを設定しました。
※ データベースのパスワードは Secret Manager か Systems Manager Parameter Store を使うべきですが、ここではテストのために設定しています。
Lambda レイヤーを追加
Lambda レイヤーは、所定のファイル構造に沿ってライブラリを Zip 圧縮し、AWS マネジメントコンソールでアップロードして使います。
詳細は ドキュメント に記載されています。
Cloud9 で SQL Alchemy と PyMySQL を pip インストールしました。
それを zip で固めました。
mkdir python
cd python
pip install -t . sqlalchemy
pip install -t . pymysql
cd ../
zip -r python python
出来上がった zip ファイルをダウンロードします。
Lambda コンソールから、レイヤー ページに移動します。
[レイヤーの作成] ボタンをクリックします。
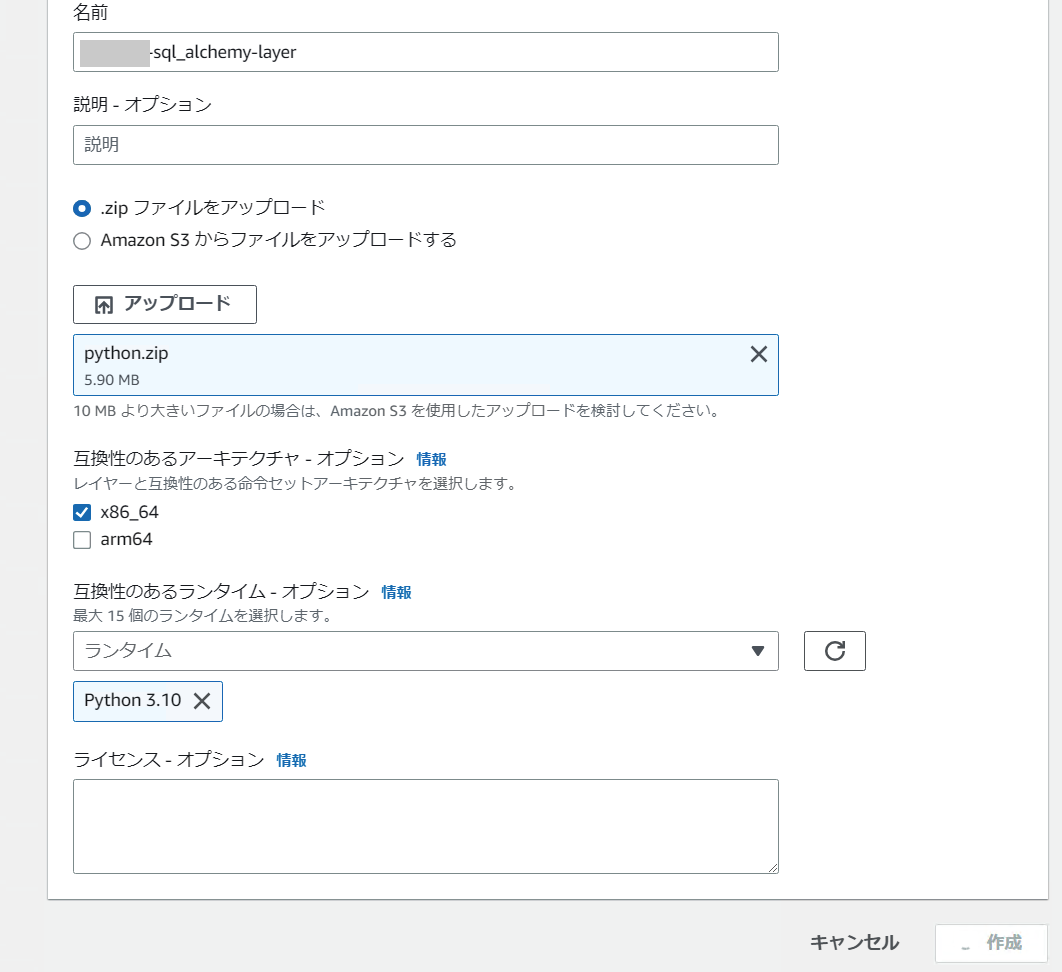
Lambda レイヤーに名前をつけて、先の手順で作成した Zip ファイルをアップロードします。
ランタイムは Python 3.10 にしました。
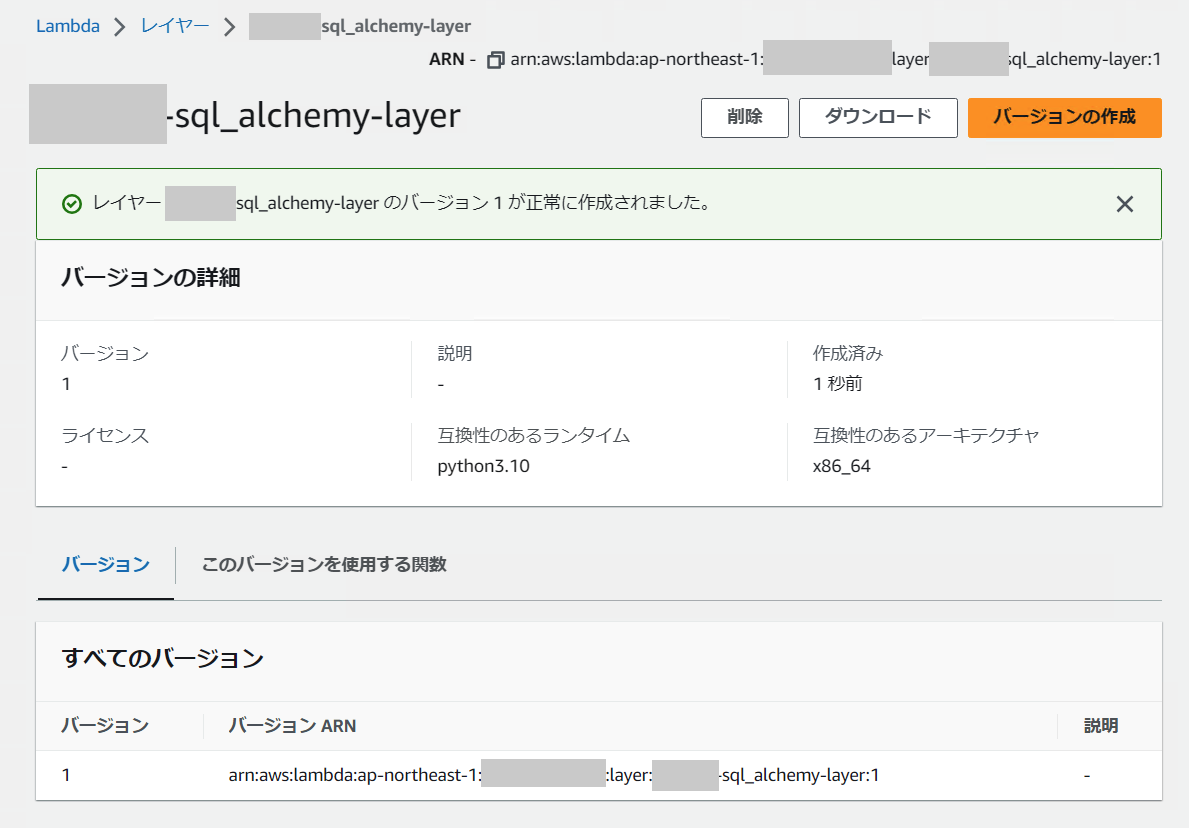
[作成] ボタンをクリックすると、Lambda レイヤーバージョン 1 ができました。
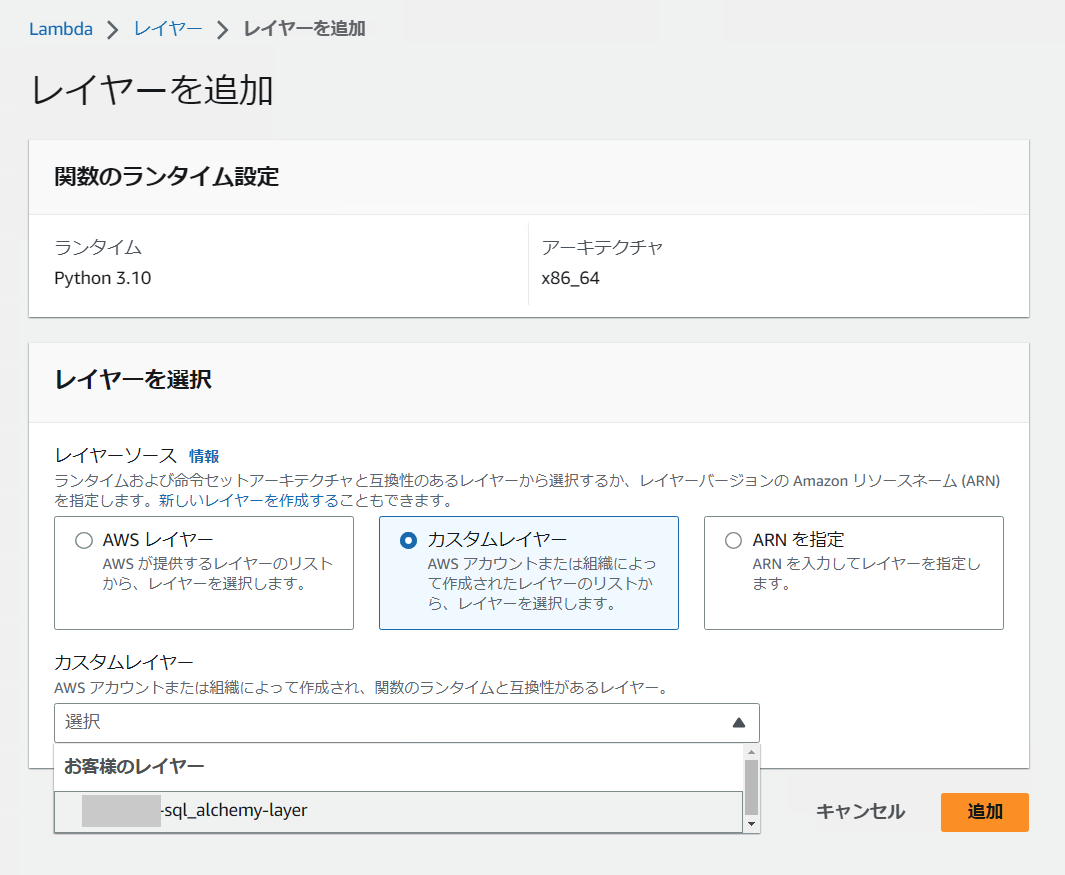
Lambda 関数のページに戻り、下部にある [Lambda レイヤーを追加] ボタンをクリックします。
[○ カスタムレイヤー] を選択して、先ほど作成したレイヤーを指定します。
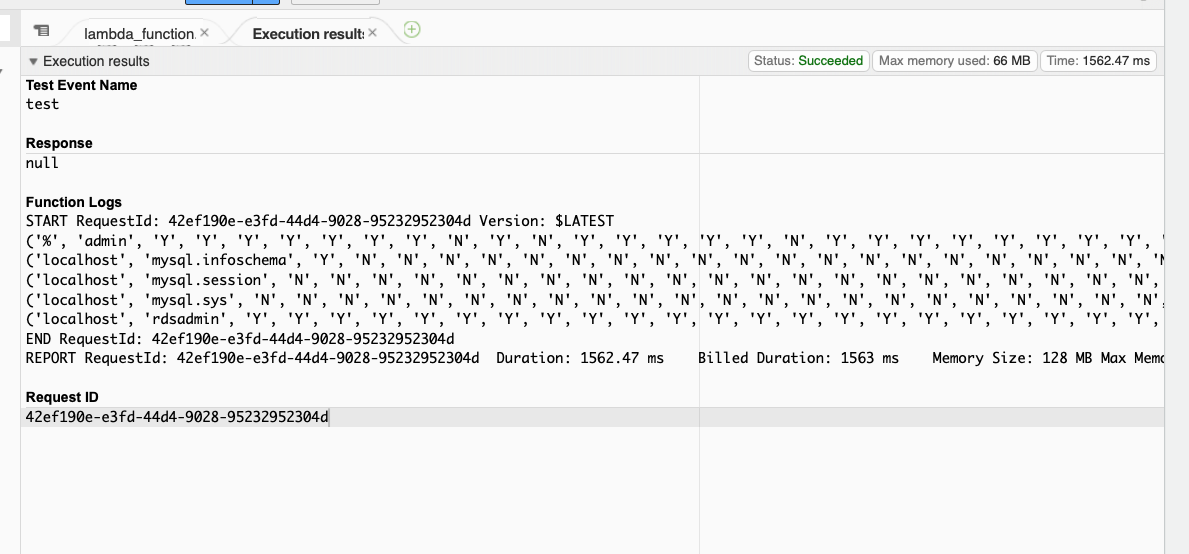
Lambda のテスト
テスト実行してみると、RDS for MySQL からユーザーテーブルが取得できました。
SQS キューを設定
Lambda 関数ができた (コーディングはアプリチームに引き継ぎました。) ので、SQS キューを設定しました。
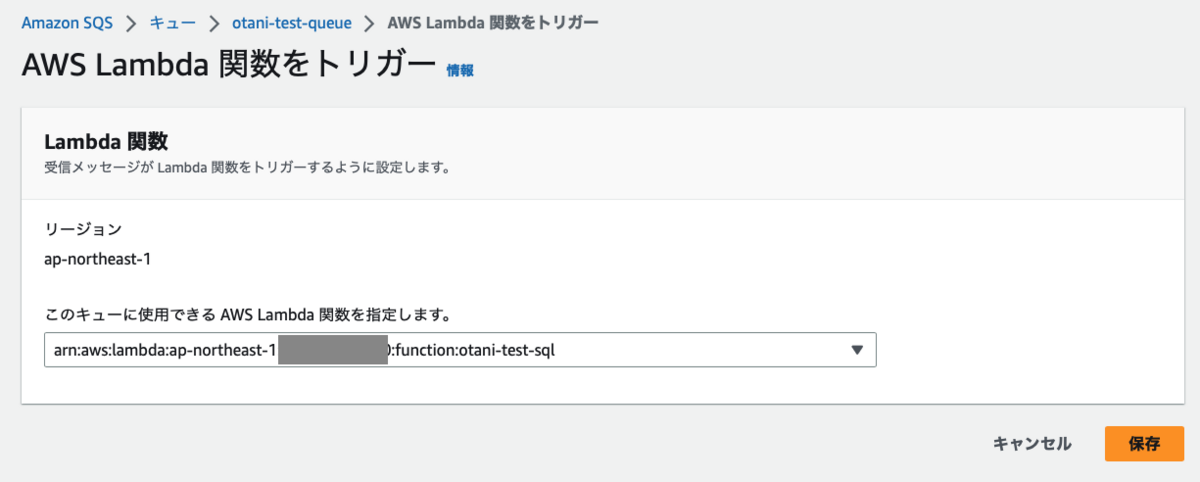
メッセージを作成し、Lambda トリガーに先ほどの Lambda 関数を指定しました。
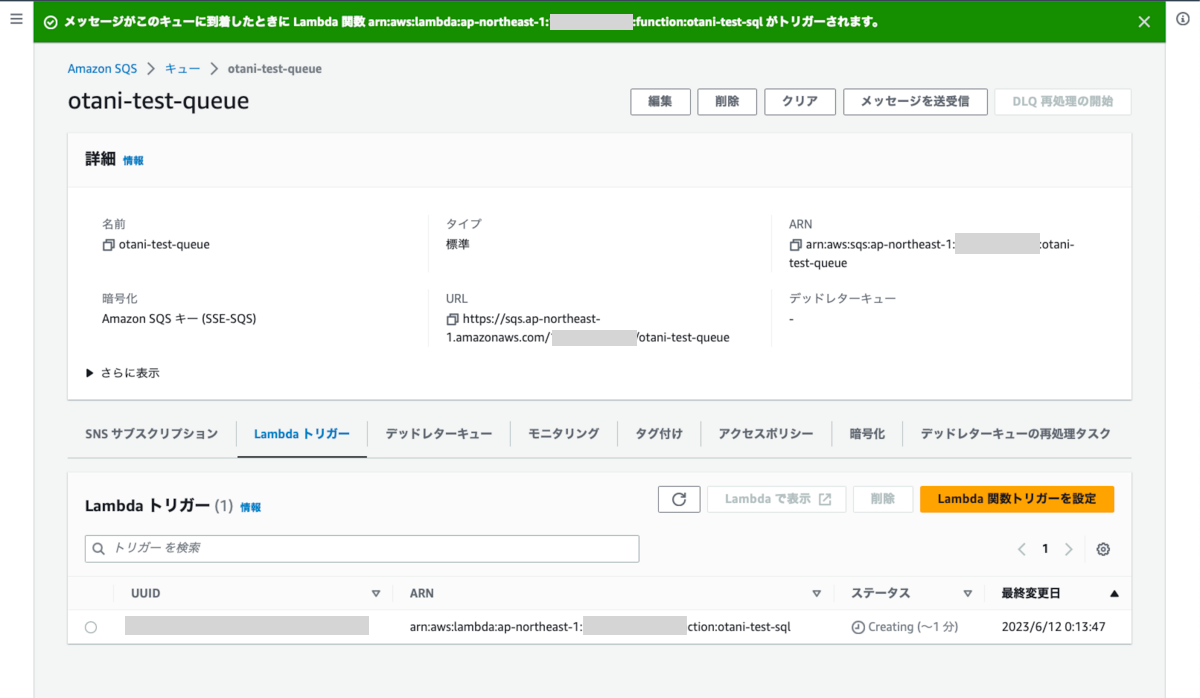
ステータスが Enabled に変わりました。

SQS メッセージをテスト送信してみます。
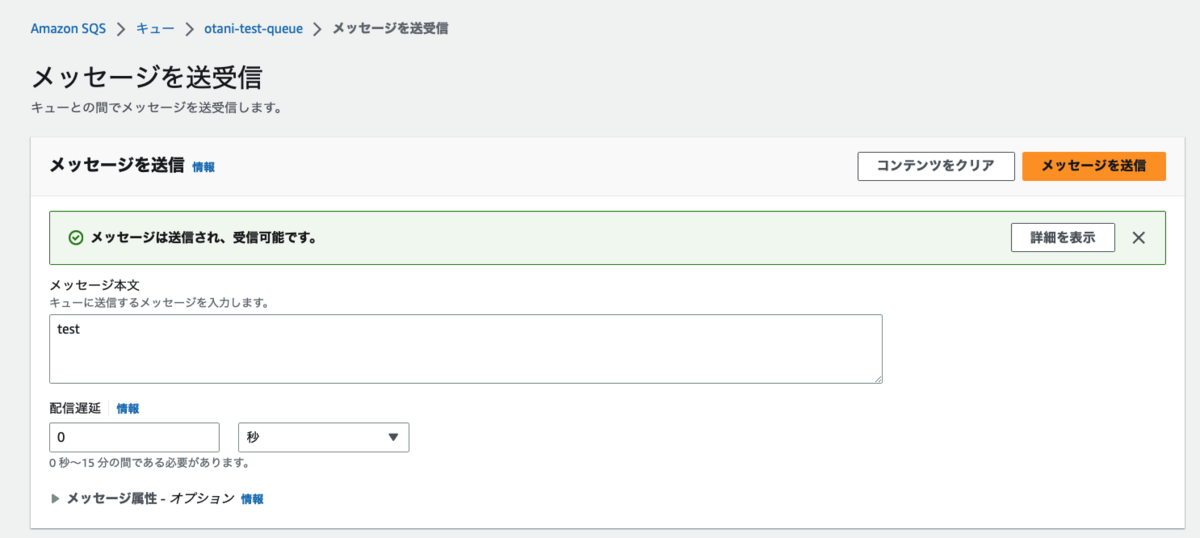
Lambda が実行されました。
AWS CLI で SQS メッセージを送信
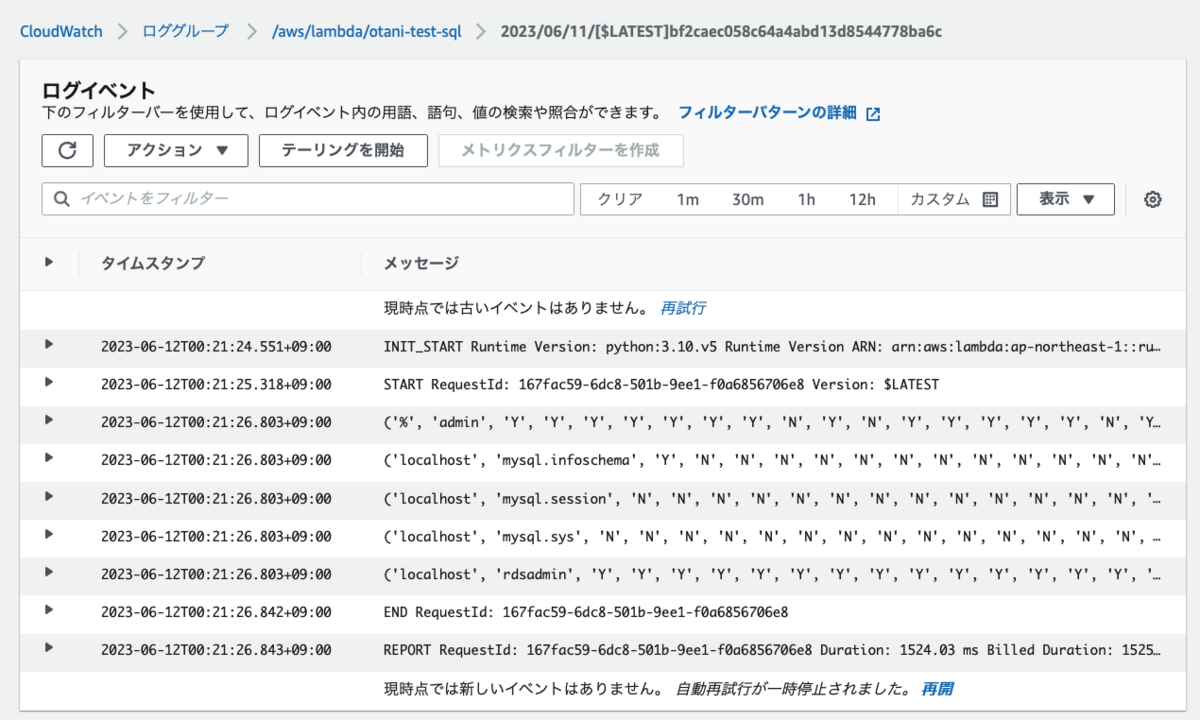
手動での挙動が確認できたので、AWS CLI リファレンス を参考に、AWS CLI にてメッセージを送信しました。
aws sqs send-message --queue-url https://sqs.ap-northeast-1.amazonaws.com/<アカウント ID>/<キュー名> --message-body "test"
EC2 から実行するには、IAM インスタンスプロフィールロールに SQS の send-message を実行する権限追加が必要です。
今回はテストのため、CloudShell にて実行しました。
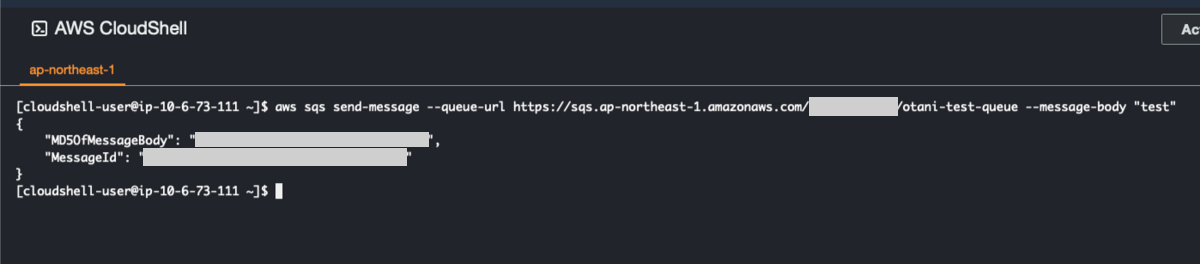
Lambda が実行されました。

同時実行数を制御する
ダウンロードボタンが複数押された際に、その都度 Lambda が実行されると、RDS に負荷がかかるため、同時実行数を制限することにしました。
Lambda のトリガーから、[編集]ボタンをクリックし
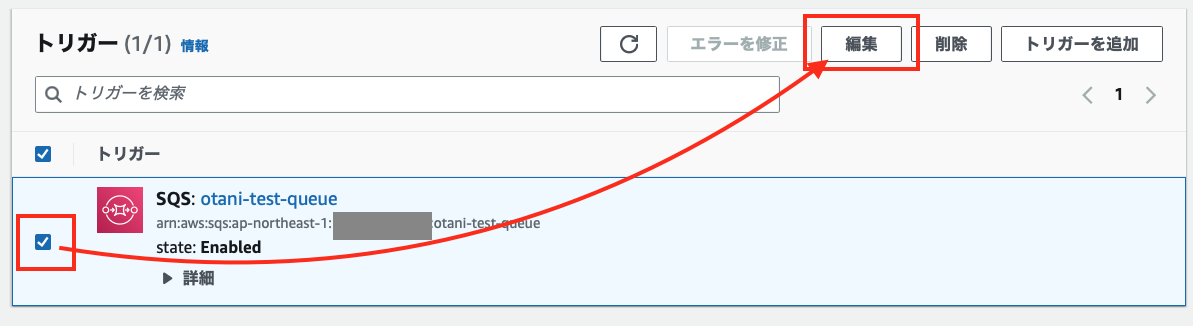
最大同時実行数を最小の 2 にしました。

また、Lambda の同時実行の予約は 3 にしました。

まとめ
今回は、SQS から Lambda が実行される部分と、Lambda が RDS に接続する部分に絞って操作と挙動を解説しました。
本アーキテクチャを採用いただけるかどうか分かりませんが、Lambda は 15 分まで実行できるので、ご希望の処理には最適ではないかと考えます。
次回、機会があれば、S3 バケットにデータをプッシュする部分と、SNS を使って通知を送る部分も解説したいと思います。
最後までお読みくださりありがとうございました。