こんにちは、AWSチームの藤岡です。
昨年末にAWSから、大規模言語モデル(LLM)に関する以下の記事が公開されました。
AutoMLツールであるSageMaker Autopilotを活用して、業界ドメインに特化したチューニングをオートメーションで行う方法を紹介しています。なかなか魅力的ですね!
そこで、本記事では、 AWSのオートメーション機能を使用したLLMのファインチューニングの手順と、RAGとの使い分けについて、ご紹介したいと思います。(結論はコチラです)
ファインチューニングとは
LLMのファインチューニングは、端的に説明すると、LLMに対してタスクやドメイン固有のデータを与えて、そのパラメータを最適化するプロセスです。これにより、特定のドメインに対してより正確で関連性の高い出力を生成できます。
※より厳密にファインチューニングについて知りたい方は、以下を参照ください。 www.anthropic.com
高い精度を実現する一方で、ファインチューニングには以下のような課題があります。
- リソースコストの高さ:大量のデータを使ったトレーニングには、計算リソースが多く必要です
- 高度な専門知識:ハイパーパラメータの最適化などチューニング作業には専門的なスキルが求められます
- 長い試行錯誤の時間:効果的なファインチューニングを行うには、複数回のトライアル&エラーが必要です
チューニングを自動化するAutopilotの魅力
上記のファインチューニングの課題に対して有効なのが、SageMaker Autopilot(以降Autopilotと記載)です。
Autopilotは、データからモデルのトレーニング、評価、デプロイメントまでのエンドツーエンドの自動化を提供します。 また、内部的に複数のアルゴリズムが試行されて、最も適したモデルが自動的に選択される機能を持っています。
上記のオートメーション機能は、ファインチューニングの課題に対して非常に有効なアプローチの1つと、私も感じました。
※なおAutopilotのページには、Canvasに移行された旨の記載がありますが、本記事執筆時点ではAPIによるAutopilotが利用可能です。
AutoMLアプローチの実践
それでは元の紹介記事で公開されているリポジトリを参照して、LLMファインチューニングをはじめましょう。(ちなみに対象ドメインは、元ブログでも説明されていますヘルスケア業界です)
なお実行環境は、私もSageMaker Studioを用いました。
※ SageMakerは昨年末に大幅更新されているので、既存のいわゆるSageMaker Studioを使用する際には、SageMaker AI (platformではありません) を使用してください。
また、SageMakerを使用するので、リソース利用料金にはご注意ください。(私は試行錯誤したので、トータルで100ドルくらい掛かりました...)
料金を抑えるために、検証以外ではJupyterはオフにする、不要になったSageMaker Studioは削除する、自分が試したいことに応じてインスタンスタイプは小さいものを選ぶなど十分に注意してください。
セットアップ
Notebook環境の準備
Jupyter Labを選択して、以下の設定で実行環境を作成・オープンします。
- インスタンス:ml.t3.medium
- ディストリビューション:Latest(2.2)
Jupyter上で、対象リポジトリをクローンしましょう。すると以下のような状態になりますので、これで準備は出来ました。
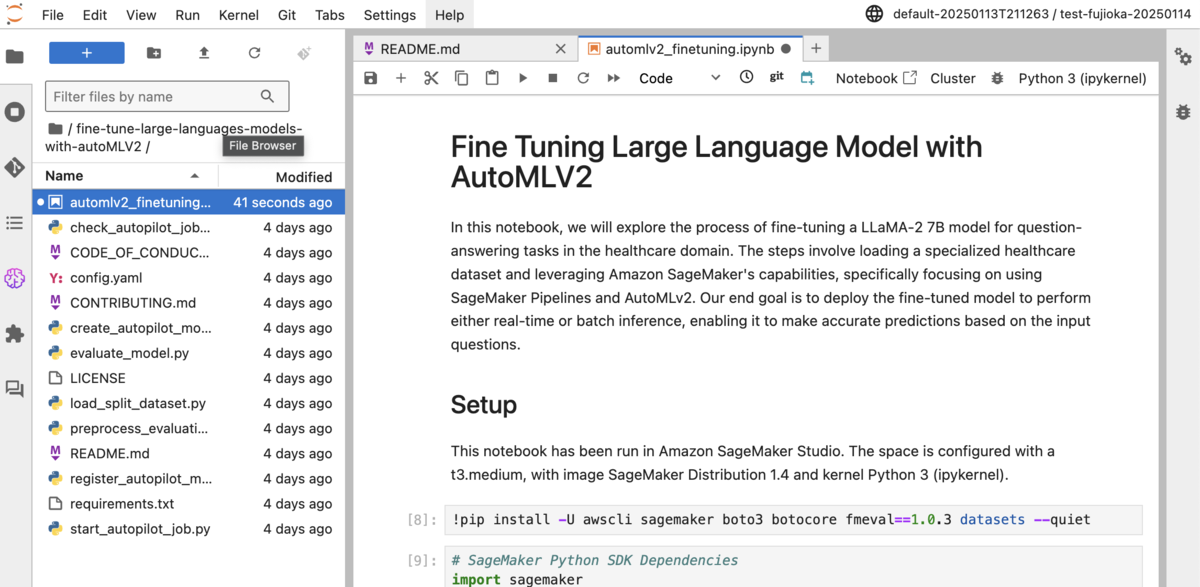
IAMの準備
後続の作業のために、Lambda実行ロールを作成します。以下のAWSマネージドポリシーと、以下JSONの権限をインラインポリシーなどを指定してください。 (ロール名は後で使用するので控えてください)
- AWSLambda_FullAccess
- AWSLambdaExecute
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Statement1", "Effect": "Allow", "Action": [ "iam:PassRole", "sagemaker:CreateAutoMLJobV2", "sagemaker:StopAutoMLJob", "sagemaker:DescribeAutoMLJobV2", "sagemaker:ListCandidatesForAutoMLJob", "sagemaker:ListAutoMLJobs", "sagemaker:CreateModel", "sagemaker:CreateEndpoint", "sagemaker:CreateEndpointConfig" ], "Resource": "*" } ] }
次に、SageMakerのロールに権限追加をします。IAMロールコンソールから、「AmazonSageMaker-ExecutionRole-YYYYMMDTHHMMSS」(日時はSageMaker Studioの作成日になります)を選択して、以下のようなインラインポリシーなどで追加してください。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Statement1", "Effect": "Allow", "Action": [ "lambda:*", "iam:PassRole", "sqs:*" ], "Resource": "*" } ] }
モデルのインスタンスタイプの変更
最終的にパイプラインを実行すると、モデルが作成できます。この際に事前に設定されたインスタンスタイプでは、デフォルトのアカウントでは許可されていないml.g5.12xlarge が指定されています。(めちゃくちゃ大きいですね...)
あくまでトライアルをしたいだけならば、デフォルトで許可されている、もっと小さいインスタンスタイプを指定して、パイプライン処理を成功させましょう。create_autopilot_model.py の、L67にて InstanceTypeを変更することができます。
その他の修正
requirements.txtに、s3fsを追加しておきましょう。(クローンしたままでパイプライン実行したら、以下ライブラリの不足でエラーが起きました。)
ノートブックを使ったトライアル
まずautomlv2_finetuning.ipynb を開きます。このファイルを使って、ファインチューニングのセットアップからモデル・パイプラインの作成まで体験することができますので、各セルを実行していきましょう。
進めていくと、以下のようにIAM Permissionのセルがあります。ここでlambda_execution_role_nameを、作成したLambdaロール名に置き換えましょう。

さらに進めていくと、以下のようにPipelineParameterの設定パートがあります。
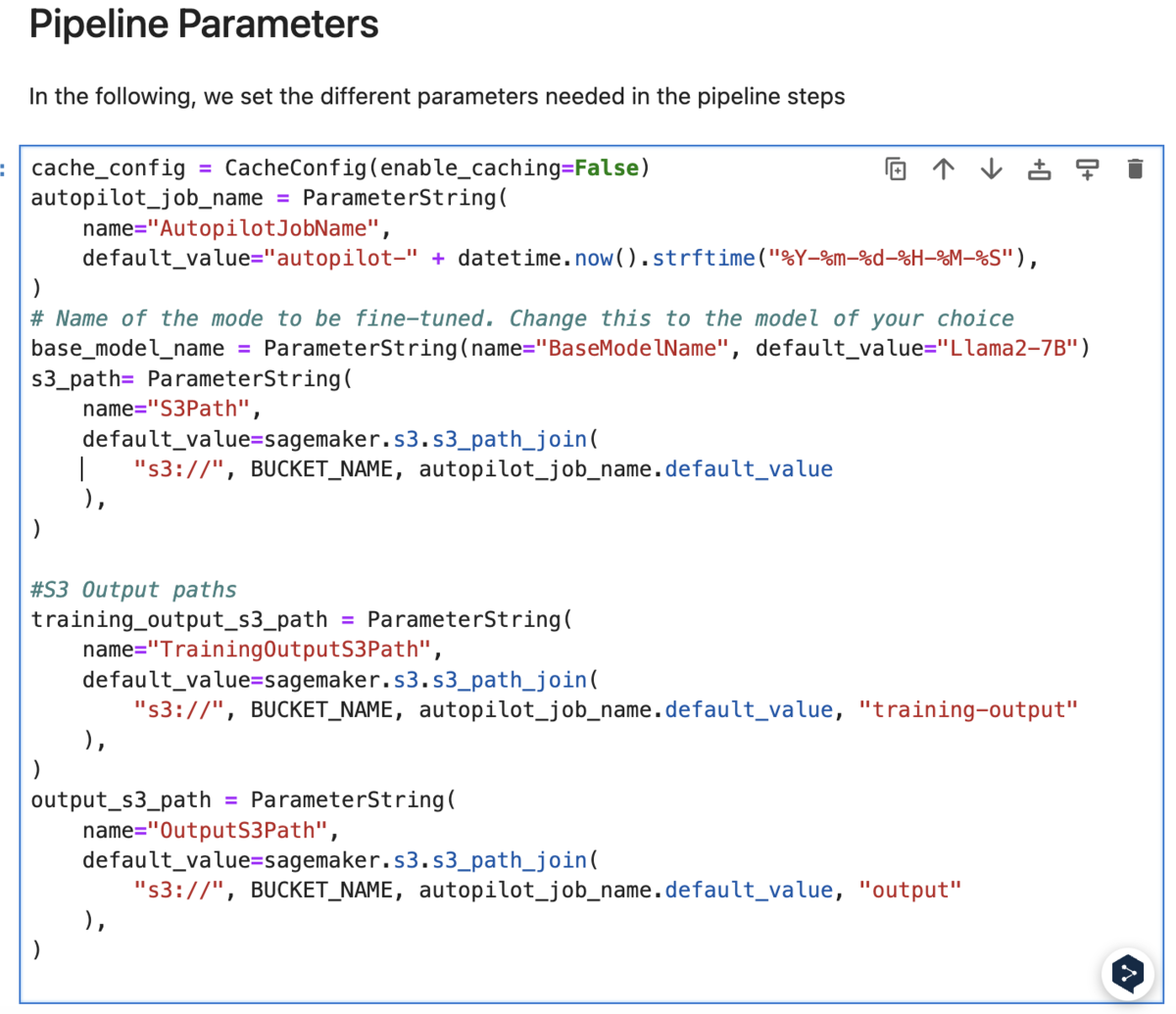
セルを見ると、Llama2-7Bが指定されています。ちなみに執筆時点(2025.01)で、Autopilotでファインチューニングに利用できるLLMは、Llamaが含まれるMeta系のLLMと、Hugging Face系のLLMのみとなっています。(この選択肢が、個人的にはちょっと物足りないですね...)
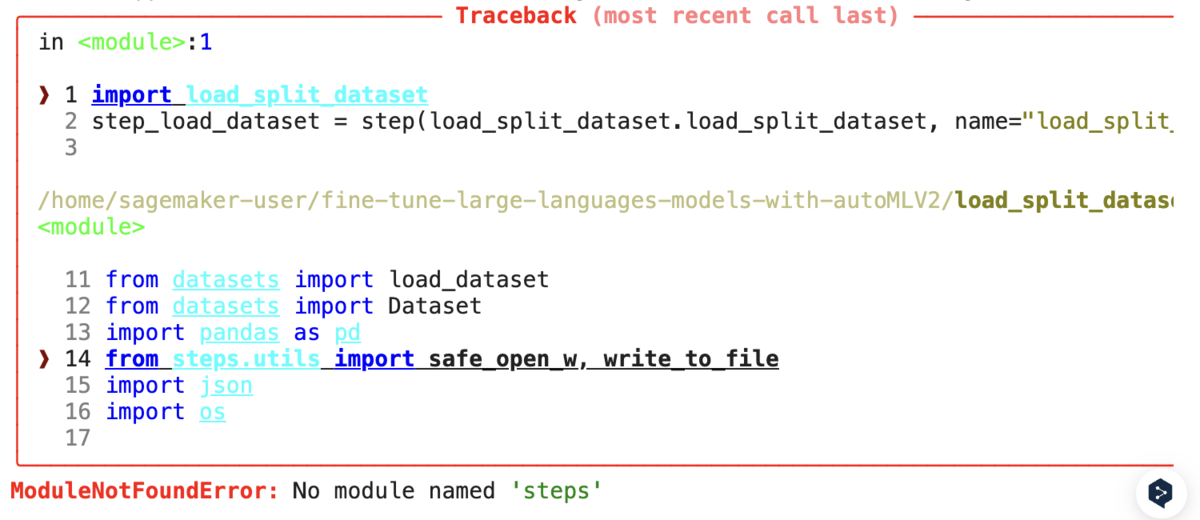
続けていくと途中で、以下のライブラリのエラーが起きました。
もしこのエラーが起きた場合には、ノートブックではなくload_split_dataset.pyの「from steps.utils import safe_open_w, write_to_file」の行をコメントアウトすることで解消します。
「Create and Run Training Pipeline」で、いよいよMLパイプラインを実行します。セルを実行後、SageMaker StudioのPipelinesから実行履歴を確認できます。
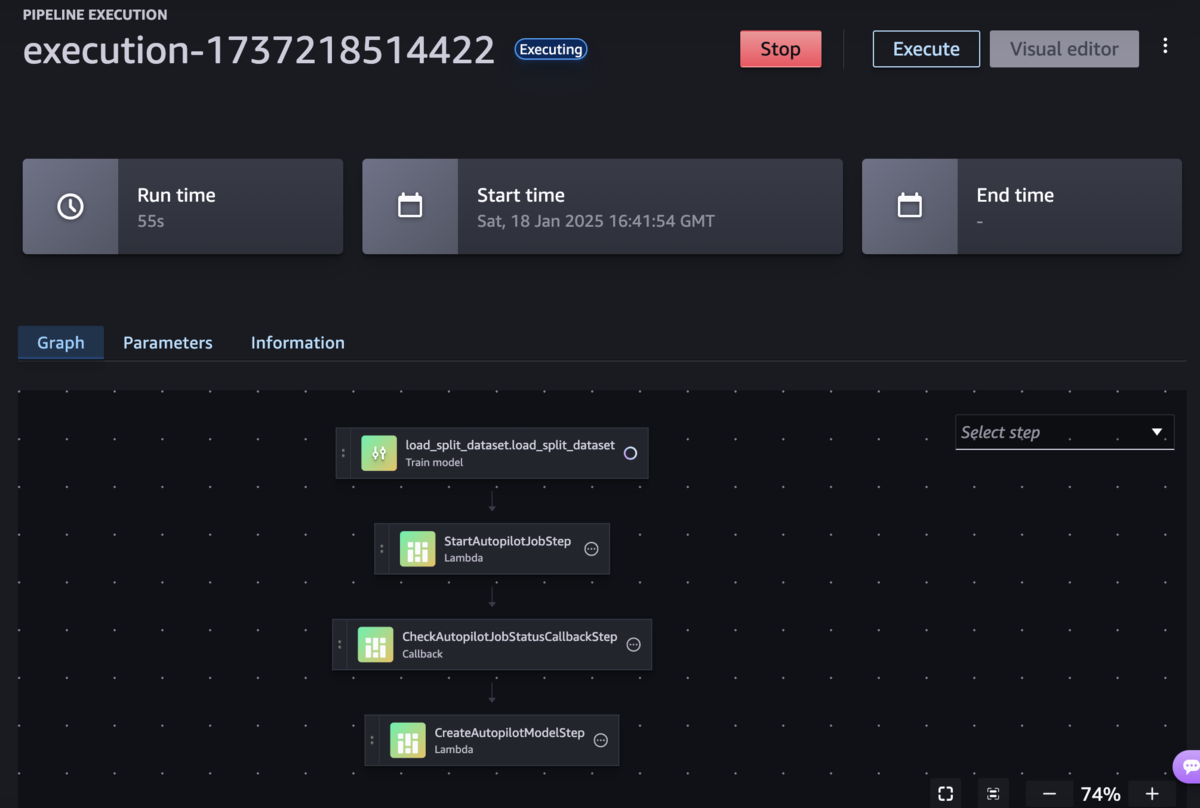
各プロセスでエラーが発生した場合、ノートブック上からは以下エラーメッセージしか表示されないため、Pipelineの実行履歴からエラーログを確認して原因を探りましょう。
WaiterError: Waiter PipelineExecutionComplete failed: Waiter encountered a terminal failure state: For expression "PipelineExecutionStatus" we matched expected path: "Failed"
上記パイプラインにて、学習フェーズが完了です。デプロイしたモデルは、SageMaker Studioのモデル一覧から確認できます。
同様に以降のセルにて、推論フェーズもパイプラインが実行され、ドメインデータで再学習したモデルによって、推論が出来ました。
最適なパラメータや評価値を1つ1つ検討・設定する場合、ファインチューニングの導入ハードルが高くなってしまいます。しかしAutopilotを使うことで、設定はAWSへお任せにしつつ、パイプラインなどSageMaker機能と組み合わせて実運用レベルのモデル学習・管理・推論が実現できました。
ファインチューニングとRAGとの使い分け
ファインチューニングは、自前で用意したデータを使った再学習によって、より適切なドメイン情報に基づいた生成精度向上が得られるのが大きなメリットです。 ただこのメリットは一見すると、「RAGでも同じように自前データを活用できるのだから、わざわざコストや時間を割いてファインチューニングする必要ないのでは?」と思えます。
そこで両者の性質を踏まえて、RAGではなく、あえてファインチューニングを行うと良いケースを2つほどご紹介します。
①モデル蒸留したいケース
モデル蒸留は、以下のAWS記事が分かりやすいので是非ご一読ください。 aws.amazon.com
簡単に言いますと、複雑で巨大なモデル(教師モデル)の知識を、小型で効率的なモデル(生徒モデル)に伝達する技術がモデル蒸留です。 ファインチューニングは再学習にコストが発生するのがネックですが、一方で運用フェーズにて、蒸留されたコスパの良い生徒モデルを多数展開することで、ランニングコストを抑えられて、トータルでRAGよりもコスト優位になる場合があります。
②自前データの更新頻度が少ないケース
RAGは外部データベースを利用して最新情報を検索し、それを元に応答を生成する手法であるため、データが頻繁に更新される場合に適しています。一方で、自前データの更新頻度が低く、安定した内容で運用可能な場合、RAGの柔軟性はそれほど必要ではありません。
このようなケースでは、ファインチューニングを用いてモデル自体にドメイン知識を直接学習させることで、よりシンプルかつ効率的なアプローチが取れます。たとえば、過去の研究データや法律文書、業界の規格といった静的なデータセットを使用するシナリオでは、ファインチューニングにより一貫性のある応答が得られます。
まとめ
SageMaker Autopilotを活用したファインチューニングは、LLMのドメイン特化や専門性向上に非常に有効な手法です。特に以下のようなケースでは、ファインチューニングが有効な選択肢となると考えられます。
- モデル蒸留したい場合:小型化されたモデルを運用することで、運用フェーズでコスト優位になる
- データの更新頻度が低い場合:安定したデータセットをモデル自体に学習させることで、より一貫性のある応答を得られる
一方で、RAGは柔軟性や最新情報への対応能力が優れており、特定のユースケースではRAGのほうが適していることもあります。両者の特性を理解し、適切に使い分けることが重要です。
更にこれらを踏まえてファインチューニングを選択した場合、機械学習の専門性を求められるチューニングが大きな課題となりますが、そこで役立つのが、今回ご紹介したAutoPilotです!
Autopilotを積極的に活用して、チューニングの複雑さを軽減し、短期間でのモデル開発成AIサービスをより手軽にリリースしましょう。