はじめに
こんにちは、AWSグループの藤岡(@fuji_kol_ry)です。
生成AIやLLMの利用が広まる中で、特定のユースケースに合わせてモデルをカスタマイズする重要性が高まっています。 前回の記事では、SageMaker Autopilotを使用したファインチューニングについて紹介して、LLMのチューニングの魅力について触れました。
Autopilotの他にも、LLMを扱うAWSサービス・プラットフォームとして、Amazon Bedrockが非常に有名です。Bedrockでは、独自のデータやユースケースに基づいたカスタムモデルの構築が可能で、以下の3つのアプローチが用意されています。
- ファインチューニング(Fine-tuning)
- 継続的な事前学習(Continued pre-training)
- モデル蒸留(Distillation)
そこで本記事では、これら3つのアプローチについてそれぞれの特長や適用シーンを整理し、使い分けのための具体的な指針を提供します。
前回の記事と合わせて、特定のユースケースに特化させたチューニングをしたい方にとっての参考になれば幸いです。
カスタムモデルのアプローチ
コンソールから、Bedrockのカスタムモデルにアクセスしましょう。
すると、以下の3つのアプローチがあります。それぞれについて説明します。
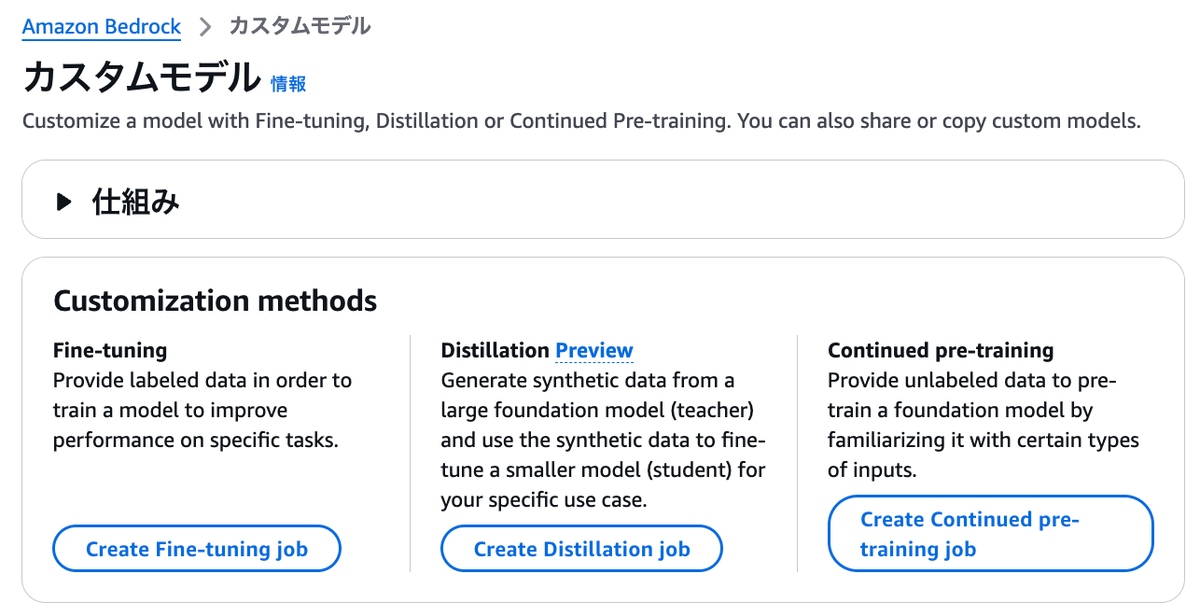
1. ファインチューニング (Fine-tuning)
LLMを、特定タスクやドメイン領域に特化させてチューニングしたい場合の選択肢となります。
ジョブ作成すると、モデルを選択することができます。選択画面は以下のように表示されます。

ここで注意するのは、表示されるモデルプロバイダーとモデルは、事前にアクセスリクエスト済みされたもの+αであることです。
※私はCohereをリクエストしたことがありませんが、なぜかプロバイダーに表示されていました。
利用可能なモデル一覧は、「アクセスをリクエスト」を押下して、モデルアクセスのコンソールから確認しましょう。
リージョンごとに利用できるモデルは、以下サイトからも確認できます。
モデル作成後、入力データとパラメータの設定を行います。
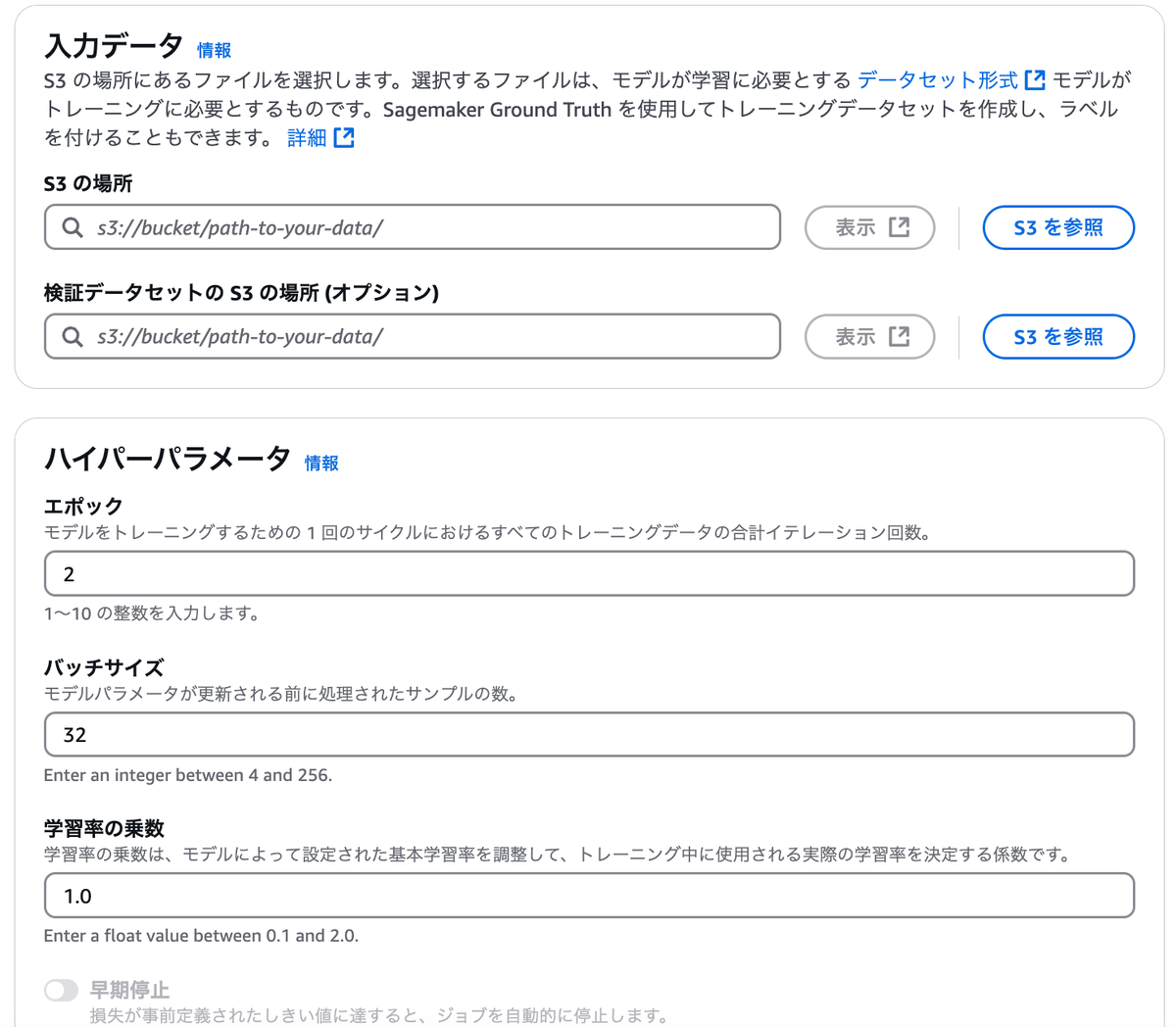
ファインチューニングの入力データは、ラベル付けされたデータセットである必要があります。ラベル付けは、Sagemaker Ground Truthの使用や、自前でのラベル付与で行います。以下サイトで説明されるようなJSON line形式(.jsonl)でデータセットを用意しましょう。
ハイパーパラメータの入力項目は、選択したモデルによって多少異なりますが、おおむねキャプチャのようなエポックやバッチサイズなどです。
ここの設定は経験や試行錯誤が必要ですね...もし難しい場合には、前回記事で紹介した、オートメーションでチューニングしてくれるAutopilotを使用するのがおすすめです。
その後、モデル検証出力先(S3バケット)を指定して、ジョブ作成を実行しましょう。ジョブが完了することで、カスタムモデルが作成されます。(以降2つのアプローチも、ほぼ同じ流れでジョブ作成できます)
カスタムモデル実行には、プロビジョンドスループットの購入が必要になりますが、カスタマイズLLMを動かすスペックになるため、利用時の料金については十分に注意してください。あくまで検証したいだけならば、推論したらすぐにクリーンナップをしましょう。(数時間で数万円掛かったりします...)
2. 継続的な (Continued pre-training)
ファインチューニングと比較して、一般知識(Ex. 最新トピック、ニュース)や更新情報を継続的に学習したい場合に有効なアプローチです。
ジョブを作成する流れは、ファインチューニングとほとんど変わりません。モデルの選択、入力データの設定、ハイパーパラメータの設定を行います。
学習データのラベル付けは任意です。必須ではありませんが、適切にラベリングすることでより効果的な学習が可能です。
3. モデル蒸留 (Distillation) ※ただしプレビュー版
モデル蒸留は、他2つとは少し異なるアプローチです。
下図に示すような蒸留プロセスを通して、教師モデルから、効率的な生徒モデルを作成することができます。(図中のように、モデル蒸留の中でファインチューニングが行われています。)
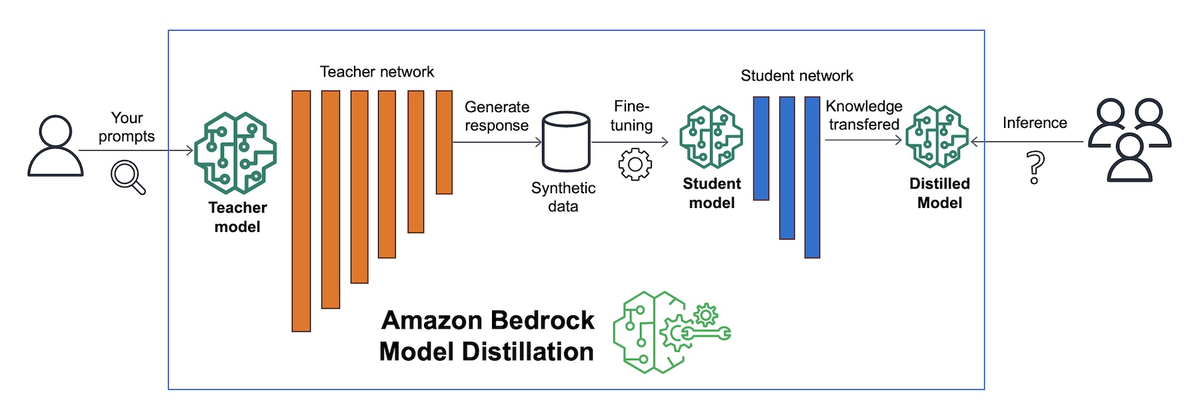
2つのモデルは以下の関係性になっています。端的に説明すると、「学習はハイスペックなモデルで行い、推論は低コスト&高速なローモデルで行う」のがモデル蒸留です。
- 教師モデル:多数のパラメータを持つ大規模なモデルによって、高精度な予測を行う。コストが高く、レスポンスも比較的遅い。
- 生徒モデル:相対的に少ないパラメータを持つ小規模なモデルによって、教師モデルの予測を再現する。コストが低く、レスポンスも速い。エッジなど実行環境に制約がある場合にも有効。
モデル蒸留ジョブを作成すると、教師モデルと生徒モデルの選択画面が表示されます。
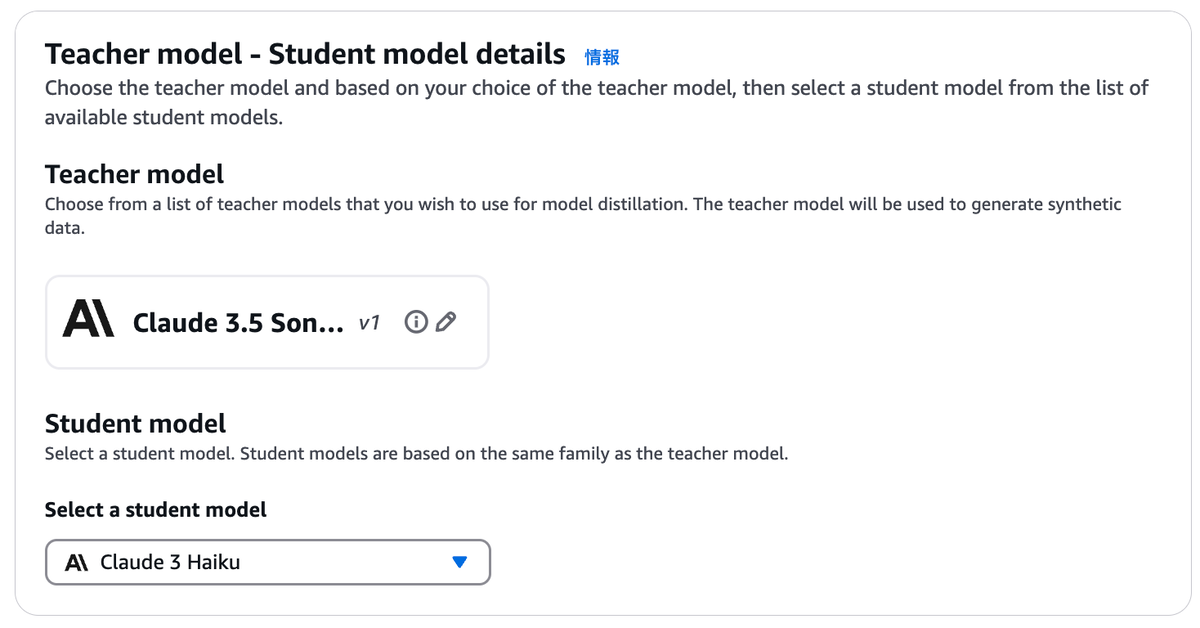
教師モデルと生徒モデルは、同じプロバイダーを選ぶ必要があります。(Ex. Nova Pro + Nova Lite, Claude Sonnet + Claude Haiku)
各アプローチのポイント
3つのアプローチを扱う上で、ポイントは大きく2つです。
①必要なケースに応じて、ファインチューニングと継続的な事前学習を使い分ける
それぞれのカスタマイズは目的が異なります。
ファインチューニングは、何か特定のタスクに対してモデルを尖らせたいケースで有効です。具体的には、特定ドメインの知識をより集中的に学習させたい場合や、(プロンプトの指定に加えて)特定タスクをより高精度にしたい場合に適しています。
一方で継続的な事前学習は、(モデルの尖りを求めるのではなく、)あくまで更新・補完が目的です。
例えば、最新ニュースや、組織の更新されたルールを学習させる場合に有効です。
ただ更新・補完することを目的とする場合には、データベースを切り離して運用することができるRAGと比較・検討することが重要です。
②ランニングコスト削減や実行環境の制約に応じて、モデル蒸留を活用する
モデル蒸留は、他のアプローチとは異なり、主にランニングコスト削減やリソース効率化を目的とします。以下のような要求が強い場合にモデル蒸留を活用すると良いでしょう。
- ランニングコストの削減:高精度な教師モデルの知識を生徒モデルに引き継ぐことで、運用フェーズでの推論コストを削減できます。
- ユースケース例:Webアプリやモバイルアプリで、大規模な推論リクエストに対応する必要がある場合など。軽量モデルを使用することで、コスト削減ができます。
- モバイル・エッジデバイスでの使用:蒸留モデルは軽量かつ高速なため、リソースが限られるエッジ環境での利用に適しています。
- ユースケース例:IoTデバイスで自然言語処理を組み込む際、蒸留された生徒モデルを使右ことで計算リソースを最適化しつつ応答速度を維持できます。
各アプローチの比較まとめ(適用シーン・注意点)
3つのアプローチを、目的や条件に応じた適用シーンなど比較して、簡潔にまとめてみました。
| アプローチ | 目的 | 適用シーン | 注意点 |
|---|---|---|---|
| ファインチューニング | 特化型モデルの作成 | 特定ドメインやタスク(例:専門分野のQAシステム) | ラベル付きデータの準備が必要で、工数が高い |
| 継続的事前学習 | モデル全体の知識更新 | 最新ニュースや法律改正の反映、ドメイン全般の知識補完 | 効果を出すにはデータ量と品質が重要 |
| モデル蒸留 | 推論コスト削減、軽量化モデルの作成 | モバイルアプリ、エッジ環境、コスト重視の運用 | 蒸留過程で精度が多少落ちる可能性がある |
また上記を元にアプローチを決定した後には、いずれもモデルのチューニング作業が必要となります。(機械学習に限らず)モデルのチューニングにはそれなりの経験やトライアル&エラーが必要となります。
そのためいざ取り組んでみたものの、チューニングのコストがペイできず実運用に採用しにくいケースや、思ったよりも精度改善に繋がらないケースがあり得ます。そのいった場合には、自前でチューニングするBedrockのアプローチ以外の選択肢として、SageMaker Autopilotの使用やRAGの採用を検討してみましょう。
まとめ
本記事では、AWS Bedrockが提供する3つのカスタムモデル作成アプローチについて、それぞれの特長や適用シーンを比較しました。
- ファインチューニング: 特定タスクやドメインに特化して、モデルに「尖り」を作成するアプローチ
- 継続的な事前学習: モデルの知識を最新状態に保つために更新・補完するアプローチ
- モデル蒸留: 軽量モデルを作成し、推論速度を向上させるアプローチ
Bedrockは、単にLLMへアクセスするプラットフォームではなく、モデルのカスタマイズ機能を通じて、実務での生成AI導入を効率化する強力なツールです。
カスタマイズする際は、コストやチームのスキルレベルを考慮しながら、ファインチューニングやモデル蒸留、Autopilotによるチューニング、RAGの活用も含めて検討しましょう。それぞれメリットがありますので、まずは小規模なデータセットやスペックで検証するして、最適なアプローチを見つけていきましょう。