こんにちは、プラットフォームビジネス事業グループ 十時(とどき)です。
生成 AI の導入が本格化するなか、RAG は社内データを安全に活かす次世代検索基盤として国内でも急速に注目を集めています。
本記事では、
Copilot Studio × Azure AI Search で Slack のやり取りを RAG 化し、Microsoft 365 Copilot から Q&A できるパイプライン
を構築してみたので、完成までの軌跡を投稿させていただきます。
- RAGが何なのか
- Copilot StudioとAzure AI Searchを使ったRAGの環境のつくり方
- SlackとRAGを組み合わせてどんなことができるのか
はじめに
RAGってなに?
RAGとは、「Retrieval Augmented Generation(検索拡張生成)」の略称で、生成AIをサポートする技術の一種です。
外部データ(自社が保有するドキュメントなど)を検索しLLMが裏付け情報を添えて回答を生成する仕組みのことをRAGと言います。
従来の LLM (Chat-GPTなど)は、学習時に取り込んだデータだけで答えを作るため、社内で更新された最新資料や機密文書は反映できません。
また、不明点を推測して誤答(ハルシネーション)するリスクもあります。
一方 RAG は、質問が来るたびにまず検索エンジンで社内ドキュメントを探し、その抜粋を根拠として LLM が回答を生成します。
これにより ①最新情報を取り込める ②回答の出典を示せる ③機密データをモデルに埋め込まず安全に使える というメリットが得られます。
Copilot Studio
Copilot StudioとはPower Platform上でCopilotエージェントをノーコードで作れる開発環境のことです。
WebやPDF、SharePoint、そしてAzure AI Searchのベクトルインデックスなど自社データを知識ソースとして登録でき、LLMが検索→生成するRAGをより簡単に構築することができます。
Azure AI Search
Azure AI Searchとは、Azure上で全文検索と生成AIを手軽に組み込めるPaaSです。
Blob上やCosmos DB、SQL Databaseなどのデータソースを対象に、自動で言語解析・ランキングを行い、REST APIやSDK経由で高速検索できます。
また、データのインデクシングにはベクター化(ベクトル化)も対応しております。
インデクシングとは、検索エンジン(Azure AI Search)のデータベースに登録して、検索できるような状態にすることを言います。
また、ベクター化とは自然言語の単語や文をベクトルに変換する技術のことです。
このデータをベクトル化する処理のことをEmbedding(エンベディング)といいます。
データのベクター化によって、単語が一致するような全文検索ではなく、「意味が近い」結果を取得することができます。
このベクターインデクシングしているデータに対して、Copilot Studioと連携ができます。
なので、Copilotで質問する→Azure AI Searchに存在する質問内容に近いデータを検索してLLMが回答する、というフローが成り立つわけです。
事前準備
今回の検証環境を構築するにあたって、事前に以下を準備します。
ライセンス
M365管理センターのマーケットプレイスより購入できます。
- Microsoft Copilot Studio(試用版)
- Microsoft Copilot Studio ユーザーライセンス(試用版)
- Microsoft 365 Copilot
※Microsoft Copilot Studio(試用版)を購入する際に"更新設定画面"が表示されます。
その際には自動更新を無効化してください。
有効化してしまうと試用期間が過ぎた際に有償版のCopilot Studioに勝手に更新されてしまいます。
PPAC環境作成
PowerPlatform管理センターにてCopilot Studioで使用する「環境」を作成します。
「環境」とはPower Platform 上に用意された “チーム専用の作業部屋” のようなもので、必ず作成する必要があります。(Azureでいうリソースグループに近いです)「環境」作成後、検証を行うユーザーに"Environment Maker"のロールを割り当てます。
Storage Account作成
SlackAPIによって取得したJSONデータを格納するストレージを作成します。
埋め込みモデル作成
Blob上のデータをAI Searchにベクター化してインデクシングする際に使用する埋め込みモデルをAzure Open AIにて作成します。
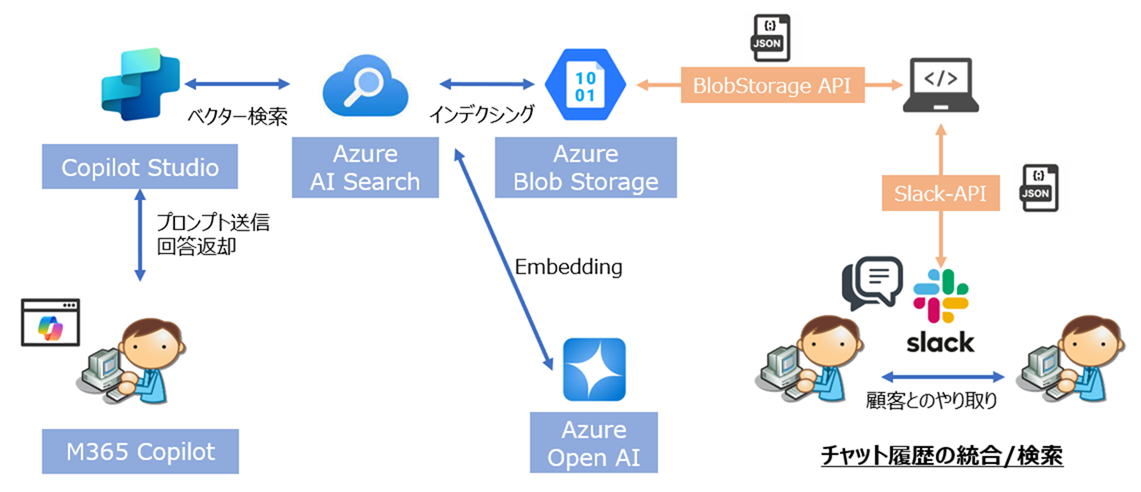
検証構成
今回の検証環境は以下のコンポーネントより構築しました。
| コンポーネント | 本検証での役割 |
|---|---|
| Slack API | 検証用チャネルへのメッセージ書込/履歴取得(JSON) |
| Azure Blob Storage | 取得 JSON の格納場所 |
| Azure AI Search | Blob 上の JSON を ベクター化インデックス化 |
| Azure Open AI | text-embedding-ada-002を 事前デプロイし、ベクター生成に利用 |
| Power Platform 管理センター | Copilot Studio 用環境の作成と権限設定 |
| Copilot Studio | 検証エージェント作成、Azure AI Search のベクター インデックスをナレッジとして追加し公開 |
| M365 Copilot | 公開したエージェントを “Chat” UI から呼び出し、プロンプト入力で回答取得 |
全体の構成図は以下のようになります。
シーケンス図もそれぞれ載せておきます。
Slackのデータ取得→JSON保存→Blobへ転送までのフロー
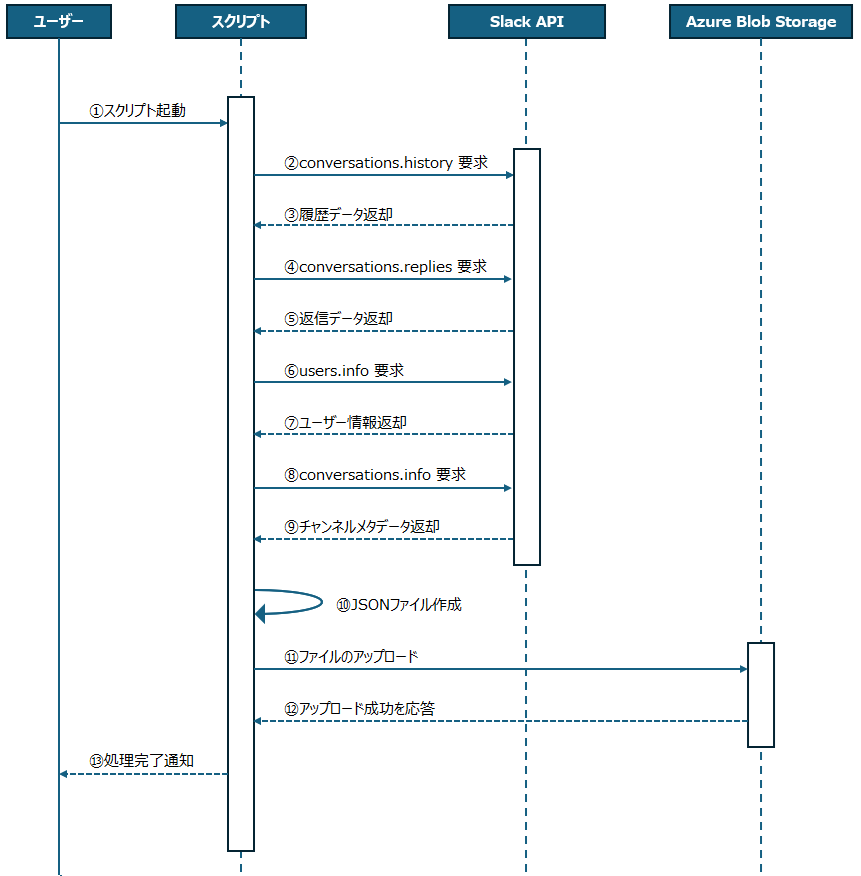
①ユーザー → スクリプト
Slackデータ取得&Blob転送スクリプトを起動します。
②スクリプト → Slack API
conversations.history によってSlackのチャネル上の履歴から親メッセージ及びメタデータを要求します。
③Slack API → スクリプト
親メッセージ及びメタデータが返却されます。
④スクリプト → Slack API
conversations.replies によって親メッセージに対するリプライメッセージ及びメタデータを要求します。
⑤Slack API → スクリプト
親メッセージに対するリプライメッセージ及びメタデータを要求します。
⑥スクリプト → Slack API
users.info によってSlackのユーザー名の情報を要求します。
※conversations.historyやconversations.repliesではユーザーIDは取得するけどユーザー名は取得できないため
⑦Slack API → スクリプト
ユーザー名の情報が返却されます。
⑧スクリプト → Slack API
conversations.info によってチャンネルのメタデータを取得します。
⑨Slack API → スクリプト
チャンネルのメタデータが返却されます。
⑩スクリプト → スクリプト
取得したデータを元にJSONファイルを作成します。
⑪スクリプト → Azure Blob Storage
生成したJSONファイルのアップロードを行います。
⑫Azure Blob Storage → スクリプト
アップロードが成功した旨が応答されます。
⑬スクリプト → ユーザー 一通りの処理が完了した通知が届きます。
Blob上のデータをAzure AI Searchにインデクシングまでのフロー
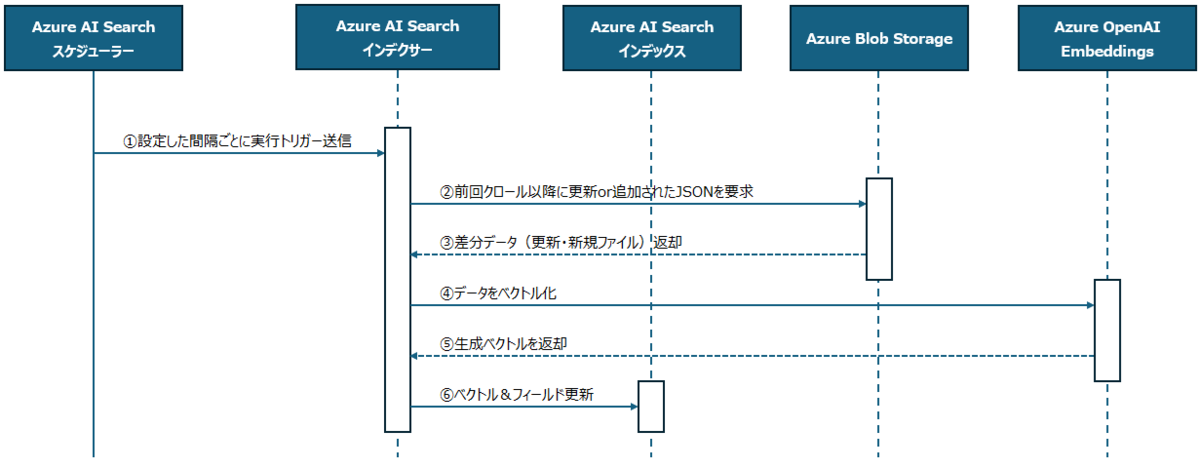
①Azure AI Search スケジューラ → Azure AI Search インデクサー
設定した間隔ごとにインデクシングの実行トリガーを送信します。
②Azure AI Search インデクサ → Azure Blob Storage
前回クロール以降に 更新または追加 された JSON を要求したします。
③Azure Blob Storage → Azure AI Search インデクサー
差分データ(更新・新規ファイル)が返却されます。
④Azure AI Search インデクサー → Azure OpenAI Embeddings
エンベディングモデルがデータをベクトル化します。
⑤Azure OpenAI Embeddings → Azure AI Search インデクサー
生成されたベクトルが返却されます。
⑥Azure AI Search インデクサー → Azure AI Search インデックス └ ベクトル&フィールドを書き込み、既存レコードを更新します。
ユーザーかCopilotに質問してから回答が返ってくるまでのフロー
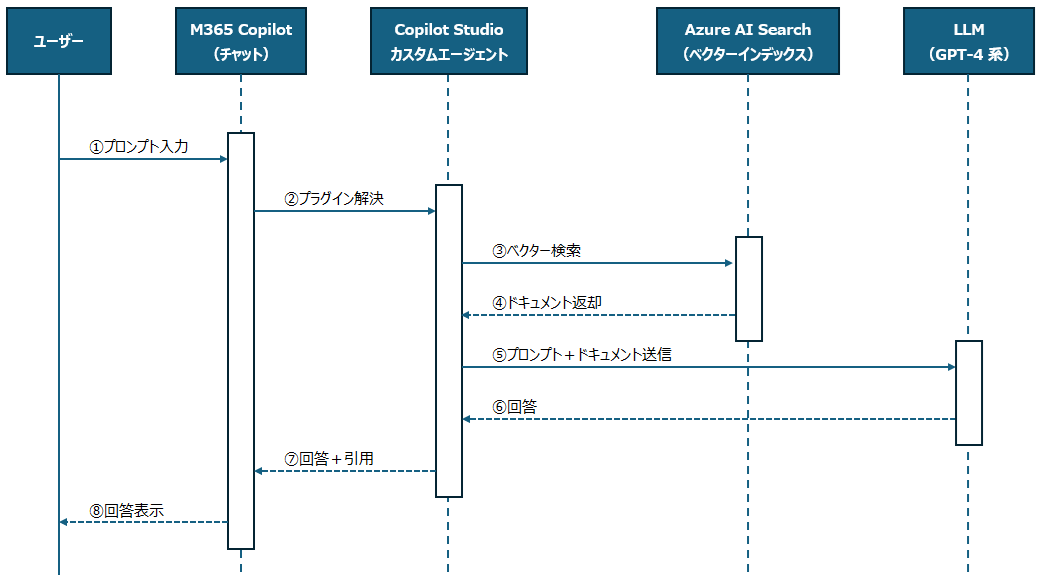 ① ユーザー → M365 Copilot(プロンプト入力)
① ユーザー → M365 Copilot(プロンプト入力)
ユーザーがで任意の質問をチャットに入力します。(入力したデータを「プロンプト」と言います)
例:「この契約書にリスクはある?」「社内ポリシーを教えて」等、、
② M365 Copilot → Copilot Studio(プラグイン解決)
プロンプトを受け取った後、指定しているエージェントが有効か、利用権限があるかを確認します。
Power Automateなどを有効にして、ほかに同時に動かすツールがないかを確認して、必要なら一緒に呼び出します。
これらの過程を経て、ようやくプロンプトがエージェントに渡されるわけです。
このような「確認して、渡す」という一連の流れのことを「プラグイン解決」といいます。
③ Copilot Studio → Azure AI Search(ベクター検索)
ユーザーの意図に基づくクエリを生成し、社内データに対してベクター検索を実行します。
④ Azure AI Search → Copilot Studio(ドキュメント返却)
ベクター検索結果によって関連するドキュメントの一部をCopilot Studioへ返却されます。
⑤ Copilot Studio → LLM(プロンプト+ドキュメント送信)
ユーザーの質問と取得した検索結果(ドキュメントの一部)を統合してプロンプトを生成し、LLMに送信します。
⑥ LLM → Copilot Studio(回答)
LLMが質問に対する自然言語の回答を生成し、Copilot Studioへ返却されます。
⑦ Copilot Studio → M365 Copilot
回答文と引用元情報をM365 Copilotに返却されます。
⑧ M365 Copilot → ユーザー
回答をユーザーにチャット形式で表示されます。
環境構築手順
Slack データ取得スクリプト作成
まずは、スクリプトの作成です
スクリプトではSlackAPIを使いたいのですが、SlackAPIを使うためには事前にSlackのアプリ開発画面にて、Slackアプリを作成して、そのアプリに権限を与える必要があります。
そのアプリをSlackの任意のチャネル上に追加することで、与えた権限に応じてメッセージのやり取りを取得できたり、メッセージを書き込んだりすることができます。
Slackの特定のチャネルからデータを取得するためのアプリをslack apiページにて作成します。
作成するアプリには、[Oath &Permissions]の[Scpoes]より以下のOAuth Scopeを追加します。
※ここで必要な権限を追加してます。
- channels:history
- channels:join
- channels:read
- users:read
追加後、同画面内の[OAuth Tokens]よりアプリのインストールを行います。
インストール完了後、Slackの任意のチャンネルを選択し、[チャンネル名]→[Integrations]→[Add apps]の順にクリックし、作成したアプリを追加すればOKです。
その後は、以下を参考にSlack API 及びBlobStorage APIを用いてSlackのデータ取得及びBlobへの転送のスクリプトを作成します。
※本記事ではスクリプトのソースコードは省略いたします。
今回の検証ではシーケンス図のように、Slack上のやり取りを取得してJSON形式のデータでBlob上に保存するスクリプトを作成しました。
Azure AI Search 作成
以下を参考にAzure AI Searchを作成します。
※TierはStandard S1以上が推奨されます。
AI Search上にBlobのデータをインデクシング
Blob上に存在するJSONのデータをAzure AI Searchにベクター化してインデクシングします。
※作成する過程で埋め込みモデルの指定が必要となるので、事前準備で作成しているモデルを指定すればOKです。
Copilot Stuidoにてエージェント作成
Copilot Studioにログインします。
画面右上の[環境]をクリックすると、環境の選択画面が右側ペイン上に表示されるので、事前準備で作成している環境を選択します。
環境を変更後にエージェントを作成します。
※エージェントとは独自開発したCopilotみたいなものだと思ってもらえればOKです。
ナレッジ追加
ナレッジとは、エージェントが検索するデータソースのことです。
今回は以下手順よりAzure AI Searchにインデクシングされているデータをナレッジとして追加します。
トピック追加
トピックとはCopilotの回答のテンプレートのようなものです。
今回は生成型の回答ノードを追加します。
補足として、なぜこの作業を行う必要があるかについてCopilot Studioの仕様を観点に説明します。
先ほど、ナレッジとしてAI Searchのインデックスを指定しました。
これで、検索対象がインデックスのデータのみに限定されるかというと、そういうわけではないんです。
Conversational boostingという機能(トピック)があり、これが発動すると、モデルは 自分の一般知識 で補完回答を生成することがあります。
これは “インターネット検索” ではなく、GPT-4 系モデルに元々学習済みの知識を使う挙動で、Copilot Studioの仕様になります。
つまり、質問の内容によってはこの機能が働いて期待する回答が得られないことがあるのです。
そこで、この生成型ノードを追加し、ソースを限定することで毎ターン AI Search だけで RAG を実行します。
誤答や情報混入のリスクを排除して検証したい場合には、この設定が必須のためこの作業が必要なんですね。
M365連携
作成したエージェントをまずは使えるようにするために、エージェントの公開を行います。
公開したら、M365でもエージェントが表示されるようにします。
※M365への公開の手順にて、うまくエージェントが追加されないことがあります。
Copilot Studio側でエージェントを再度公開するとうまく追加されます。
M365にログイン後、エージェント一覧に作成したエージェント名が表示されていれば連携完了です。
独自作成したCopilotが使えるようになります。
検証
今回は検証用のSlackのチャネルに検証用ユーザーとしてアプリをいくつか追加しました。
■登場人物
- todoki
- test-user-app1
- test-user-app2
- test-user-app3
検証1:予定確認
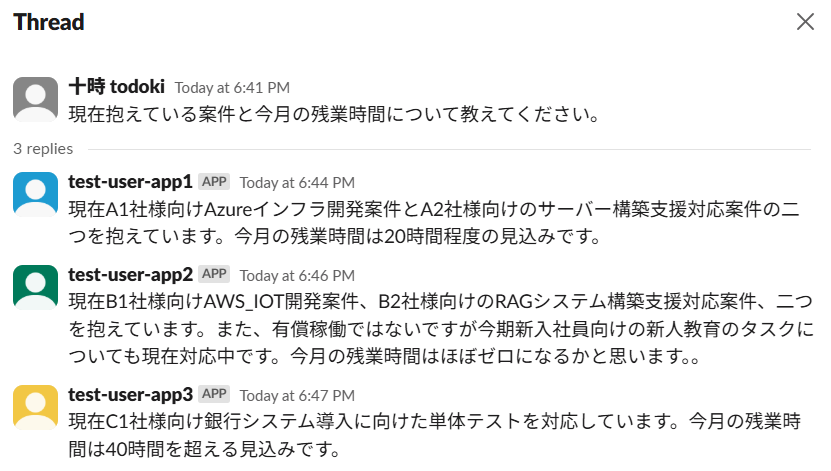
以下のようなSlackのやり取りを準備しました。
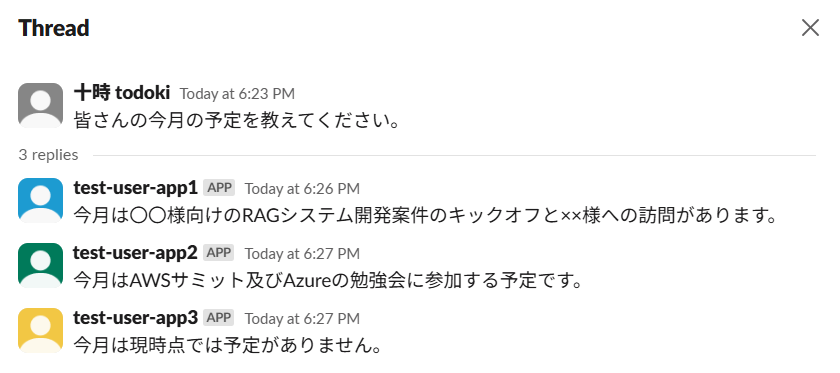
検証用ユーザーの予定を確認してみます。
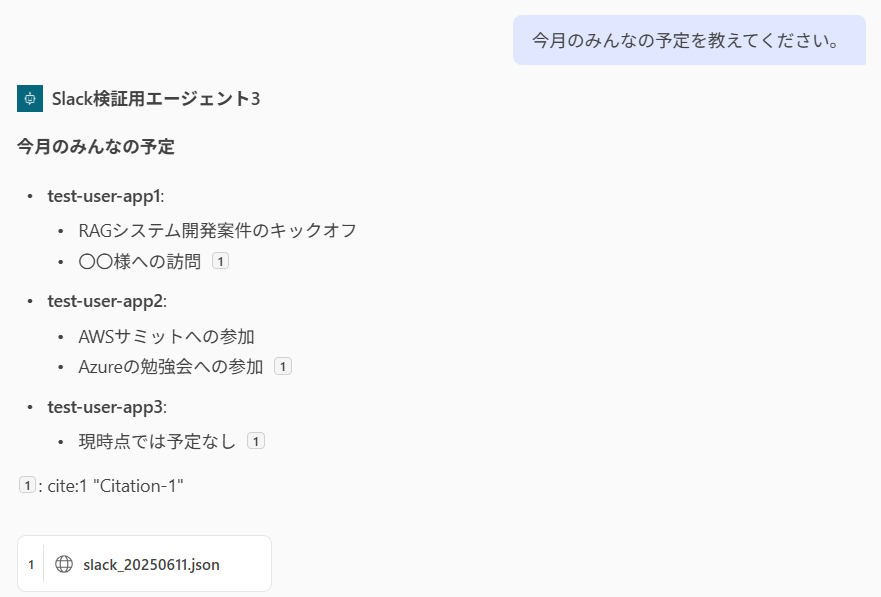
期待通りの回答が返ってきましたね。
チャネル内で予定を共有する体制の会社であればこのメッセージ一発で把握できます。
検証2:数値計算
以下のようなSlackのやり取りを準備しました。
残業時間の平均と、残業時間が30時間を越えそうな人を調べてみます。
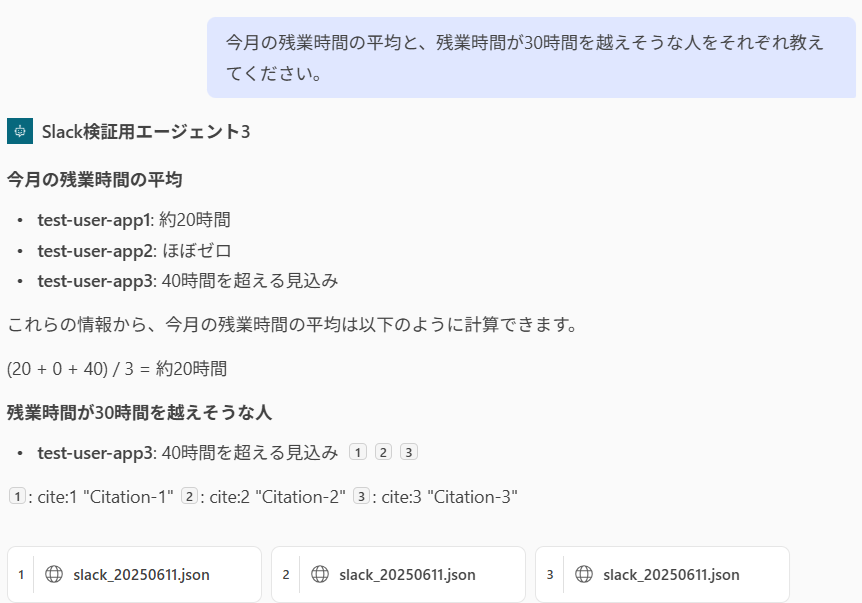
平均残業時間と、30時間を超えそうなtest-user-app3だけが回答されました。
今回は簡単な計算でしたが、AIモデルがGPT-4なのである程度複雑な計算でも対応してくれます。
検証3:ユーザー貢献度分析
以下のようなメッセージのやり取りを準備しました。
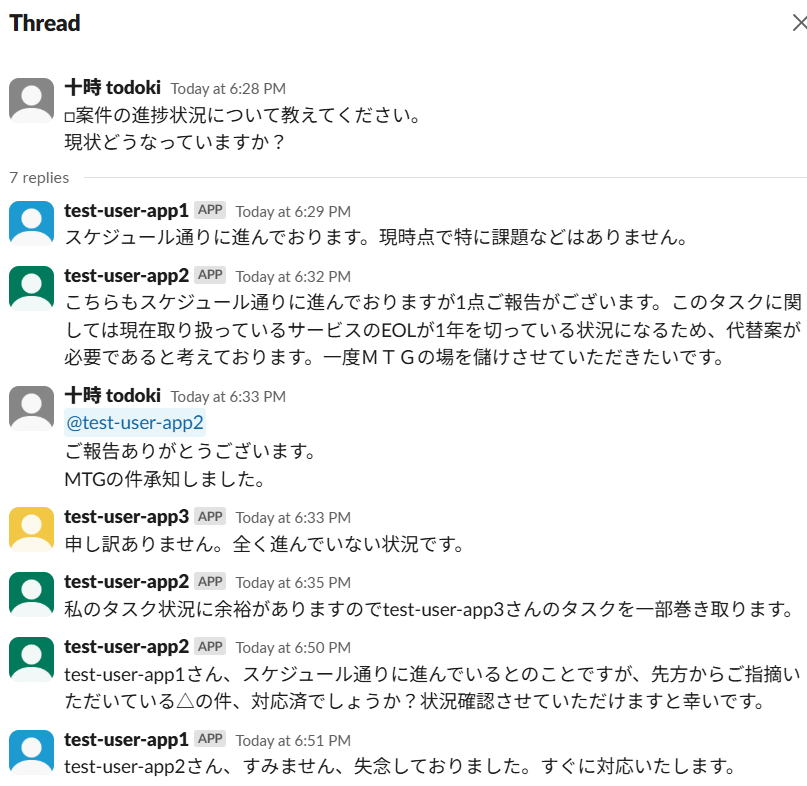
まさによくありそうなやり取りですね。
test-user-app2が他人のタスクも巻き取ったり、タスク漏れを指摘したりなどのメッセージによって貢献度を差別化しているところがポイントですね。
このやりとりをもとに、案件に対するそれぞれユーザーの貢献度を調べてみましょう。
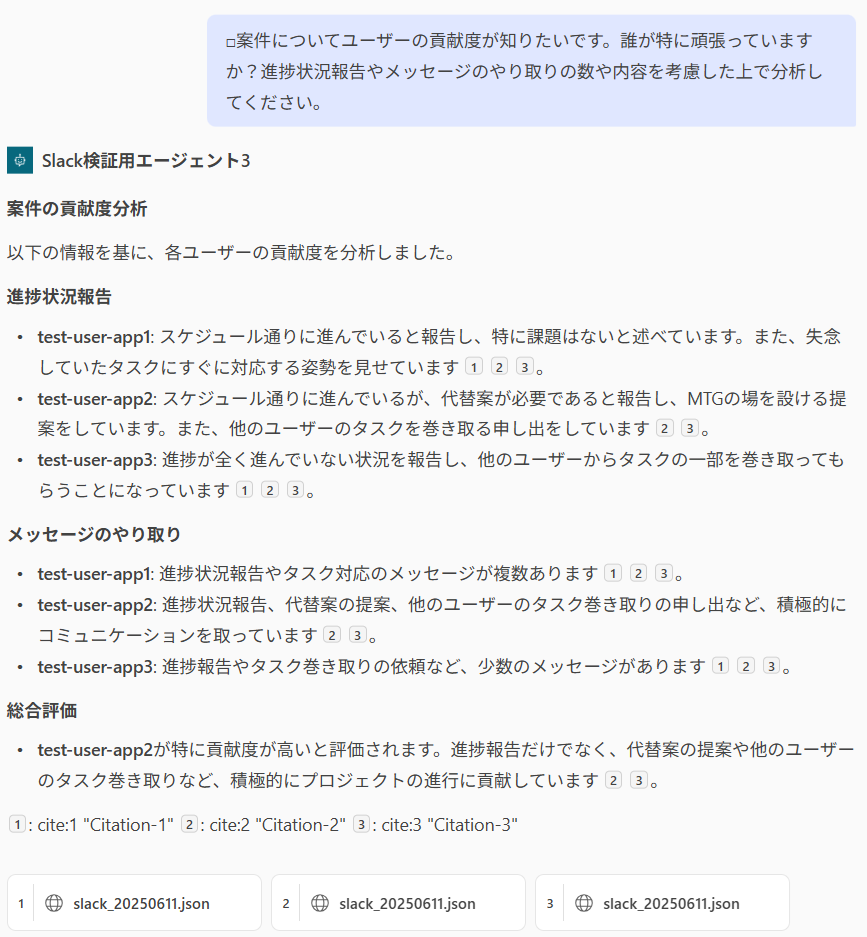
いや、すごいですね。(笑)
こちらの要望に応えて、誰がどのような理由で貢献しているかが一目瞭然となりました。
検証コストについて
今回の検証にかかったコストですが、ほぼAzure AI Search(Standard S1)によるもので約1000円くらいでした。
Azure AI Search は検索ユニット(SU)×利用時間によって料金が決まります。
つまり、データをたくさん入れても、パーティション容量に収まる限りコストは増えません。
もし費用が膨らんだら、SU 数やオプション機能をまず見直せば OK です。
また、今回はCopilot StudioとCopilot Studio ユーザーライセンスは試用版を使っているので無料で検証できましたが、30日を過ぎると30日の延長ができますが以降は有償(月200$)となります。
本記事の事前準備にも記載していますが、試用版のCopilot Studio購入時に、自動更新を無効にしていれば試用期間を過ぎたからといって自動的に有償版に切り替わることはないです。
まとめ
今回はCopilot StudioとAzure AI Searchを使ったRAG実践ということで、環境の構築方法に加えてSlackのやり取りをRAG化してみてどんなことができるのかをご紹介させていただきました。
RAGはまだ黎明期にありながら、「社内ナレッジを瞬時に意思決定へ変換する」ポテンシャルを秘めています。
今回の PoC では Slack メッセージ(親+スレッド返信)だけをナレッジに取り込みましたが、
監査ログや SaaS CRM など “静的エンドポイント” を持つデータも加えれば、RAG の網羅性は一気に高まります。
そこで候補になるのが primeNumber 社が提供している GUI-ETL の TROCCO です。
TROCCOでは100種類以上のデータソースのコネクタが標準機能として用意されているため、幅広いデータを活用することが可能です。
また、認証情報と対象テーブルを GUI で指定するだけで、 スケジュール実行やリトライまで自動化。
さらに 「プログラミング ETL」 モードを併用すれば、 GUI だけでは足りない前処理を Python で柔軟に追加できます。
将来的に Slackメッセージ取得用のコネクタが追加されれば、 今回自作した部分も GUI で置き換えられるため、
「コードレス × 拡張性」 のハイブリッドなデータ基盤が実現できると期待しています。
それでは次回の投稿もお楽しみに!